写在前面&笔者的个人总结
近年来,自动驾驶领域的3D占据预测任务因其独特的优势受到学术界和工业界的广泛关注。该任务通过重建周围环境的3D结构,为自动驾驶的规划和导航提供详细信息。然而,目前主流的方法大多依赖于基于激光雷达(LiDAR)点云生成的标签来监督网络训练。 在最近的OccNeRF研究中,作者提出了一种自监督的多相机占据预测方法,名为参数化占据场(Parameterized Occupancy Fields)。该方法解决了室外场景中无边界的问题,并重新组织了采样策略。然后,通过体渲染(Volume Rendering)技术,将占据场转换为多相机深度图,并通过多帧光度一致性(Photometric Error)进行监督。 此外,该方法还利用预训练的开放词汇语义分割模型来生成2D语义标签,以赋予占据场语义信息。这种开放词汇语义分割模型能够对场景中的不同物体进行分割,并为每个物体分配语义标签。通过将这些语义标签与占据场结合,模型能够更好地理解环境并做出更准确的预测。 总之,OccNeRF方法通过参数化占据场、体渲染和多帧光度一致性的组合使用,以及与开放词汇语义分割模型的结合,实现了自动驾驶场景中的高精度占据预测。这种方法为自动驾驶系统提供了更多的环境信息,有望提高自动驾驶的安全性和可靠性。

- 论文链接:https://arxiv.org/pdf/2312.09243.pdf
- 代码链接:https://github.com/LinShan-Bin/OccNeRF
OccNeRF问题背景
近年来,随着人工智能技术的飞速发展,自动驾驶领域也取得了巨大进展。3D 感知是实现自动驾驶的基础,为后续的规划决策提供必要信息。传统方法中,激光雷达能直接捕获精确的 3D 数据,但传感器成本高且扫描点稀疏,限制了其落地应用。相比之下,基于图像的 3D 感知方法成本低且有效,受到越来越多的关注。多相机 3D 目标检测在一段时间内是 3D 场景理解任务的主流,但它无法应对现实世界中无限的类别,并受到数据长尾分布的影响。
3D 占据预测能很好地弥补这些缺点,它通过多视角输入直接重建周围场景的几何结构。大多数现有方法关注于模型设计与性能优化,依赖 LiDAR 点云生成的标签来监督网络训练,这在基于图像的系统中是不可用的。换言之,我们仍需要利用昂贵的数据采集车来收集训练数据,并浪费大量没有 LiDAR 点云辅助标注的真实数据,这一定程度上限制了 3D 占据预测的发展。因此探索自监督 3D 占据预测是一个非常有价值的方向。
详解OccNeRF算法
下图展示了 OccNeRF 方法的基本流程。模型以多摄像头图像 作为输入,首先使用 2D backbone 提取 N 个图片的特征 ,随后直接通过简单的投影与双线性插值获 3D 特征(在参数化空间下),最后通过 3D CNN 网络优化 3D 特征并输出预测结果。为了训练模型,OccNeRF 方法通过体渲染生成当前帧的深度图,并引入前后帧来计算光度损失。为了引入更多的时序信息,OccNeRF 会使用一个占据场渲染多帧深度图并计算损失函数。同时,OccNeRF 还同时渲染 2D 语义图,并通过开放词汇语义分割模型进行监督。
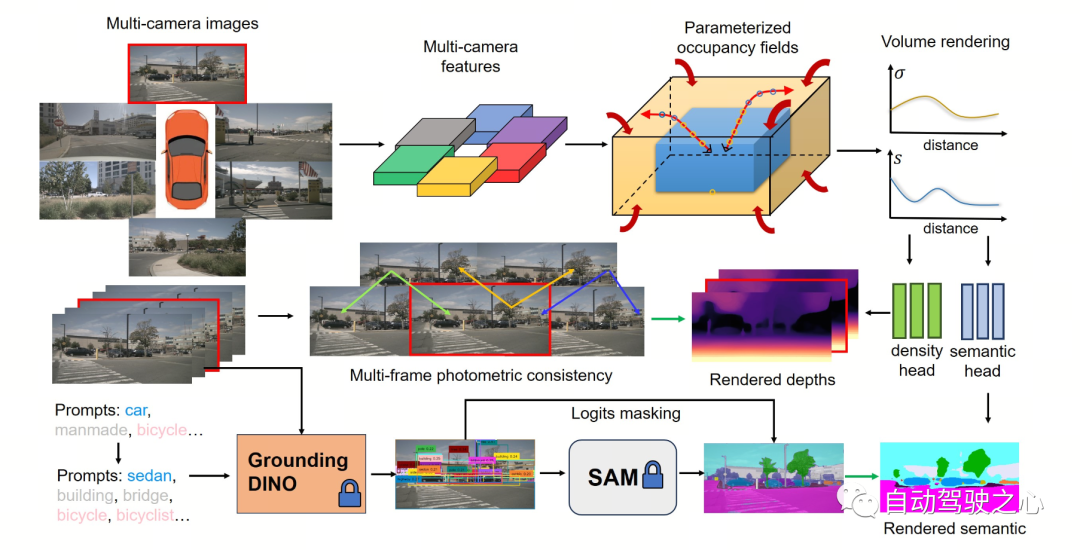
Parameterized Occupancy Fields
Parameterized Occupancy Fields 的提出是为了解决相机与占据网格之间存在感知范围差距这一问题。理论上来讲,相机可以拍摄到无穷远处的物体,而以往的占据预测模型都只考虑较近的空间(例如 40 m 范围内)。在有监督方法中,模型可以根据监督信号学会忽略远处的物体;而在无监督方法中,若仍然只考虑近处的空间,则图像中存在的大量超出范围的物体将对优化过程产生负面影响。基于此,OccNeRF 采用了 Parameterized Occupancy Fields 来建模范围无限的室外场景。
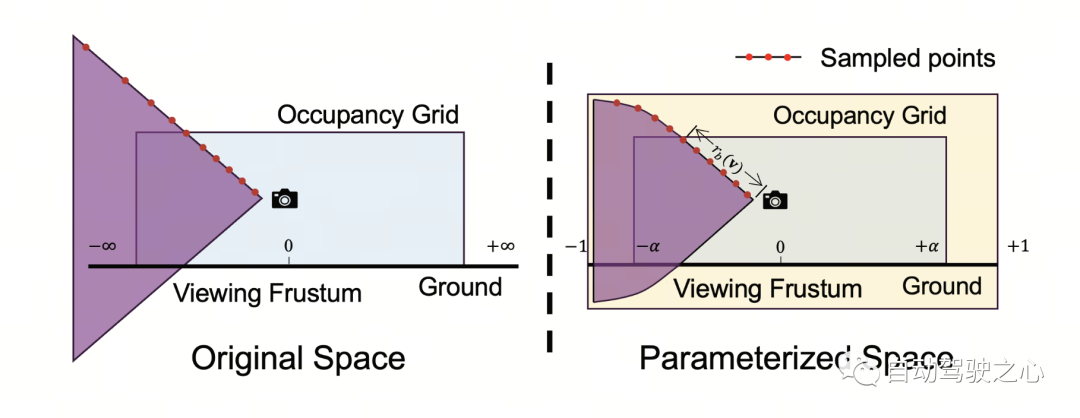
OccNeRF 中的参数化空间分为内部和外部。内部空间是原始坐标的线性映射,保持了较高的分辨率;而外部空间表示了无穷大的范围。具体来说,OccNeRF 分别对 3D 空间中点的 坐标做如下变化:
其中 为 坐标,, 是可调节的参数,表示内部空间对应的边界值, 也是可调节的参数,表示内部空间占据的比例。在生成 parameterized occupancy fields 时,OccNeRF 先在参数化空间中采样,通过逆变换得到原始坐标,然后将原始坐标投影到图像平面上,最后通过采样和三维卷积得到占据场。
Multi-frame Depth Estimation
为了实现训练 occupancy 网络,OccNeRF选择利用体渲染将 occupancy 转换为深度图,并通过光度损失函数来监督。渲染深度图时采样策略很重要。在参数化空间中,若直接根据深度或视差均匀采样,都会造成采样点在内部或外部空间分布不均匀,进而影响优化过程。因此,OccNeRF 提出在相机中心离原点较近的前提下,可直接在参数化空间中均匀采样。此外,OccNeRF 在训练时会渲染并监督多帧深度图。
下图直观地展示了使用参数化空间表示占据的优势。(其中第三行使用了参数化空间,第二行没有使用。)

Semantic Label Generation
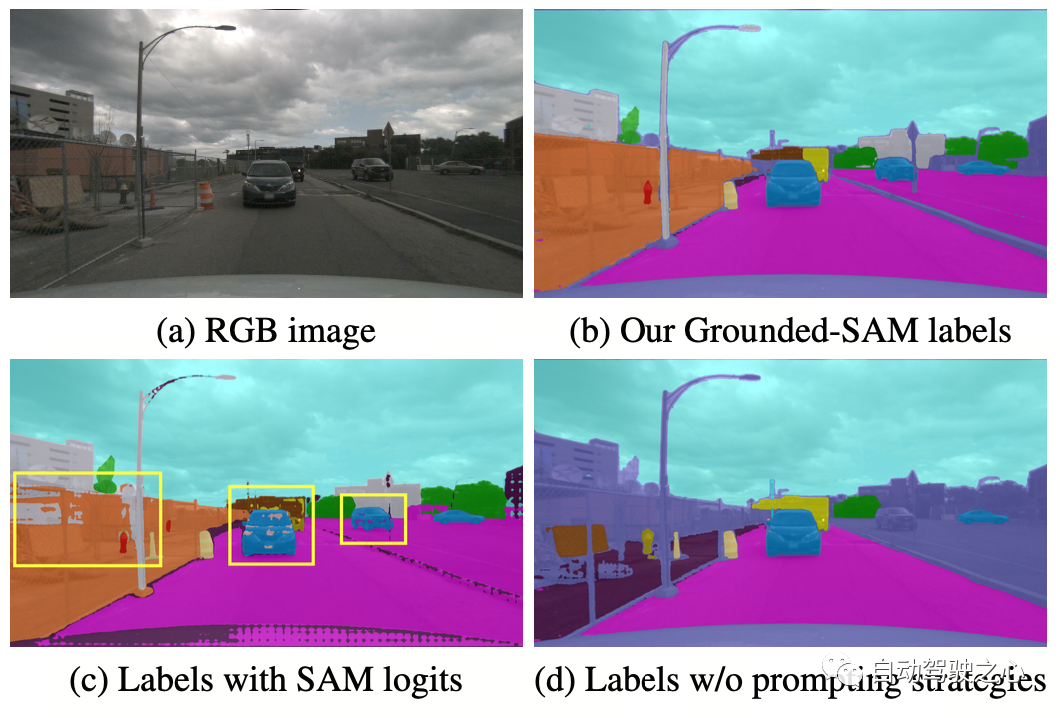
OccNeRF 使用预训练的 GroundedSAM (Grounding DINO + SAM) 生成 2D 语义标签。为了生成高质量的标签,OccNeRF 采用了两个策略,一是提示词优化,用精确的描述替换掉 nuScenes 中模糊的类别。OccNeRF中使用了三种策略优化提示词:歧义词替换(car 替换为 sedan)、单词变多词(manmade 替换为 building, billboard and bridge)和额外信息引入(bicycle 替换为 bicycle, bicyclist)。二是根据 Grounding DINO 中检测框的置信度而不是 SAM 给出的逐像素置信度来决定类别。OccNeRF 生成的语义标签效果如下:
OccNeRF实验结果
OccNeRF 在 nuScenes 上进行实验,并主要完成了多视角自监督深度估计和 3D 占据预测任务。
多视角自监督深度估计
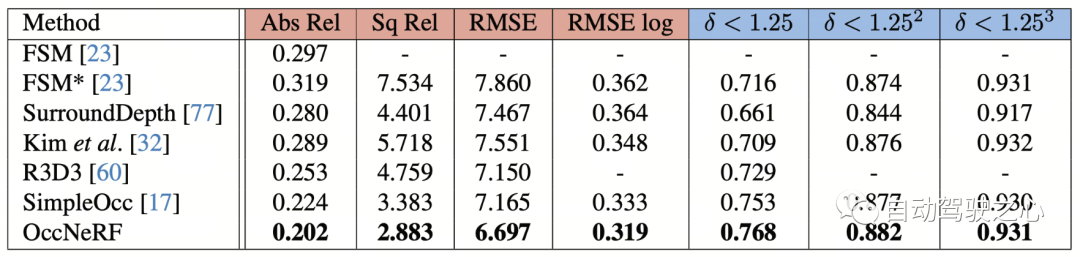
OccNeRF 在 nuScenes 上多视角自监督深度估计性能如下表所示。可以看到基于 3D 建模的 OccNeRF 显著超过了 2D 方法,也超过了 SimpleOcc,很大程度上是由于 OccNeRF 针对室外场景建模了无限的空间范围。
论文中的部分可视化效果如下:

3D 占据预测
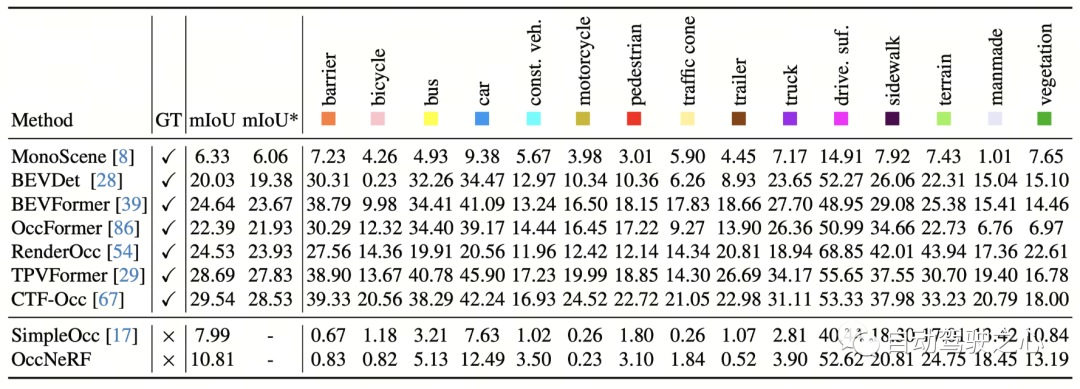
OccNeRF 在 nuScenes 上 3D 占据预测性能如下表所示。由于 OccNeRF 完全不使用标注数据,其性能与有监督方法仍有差距。但部分类别(如 drivable surface 与 manmade)已达到与有监督方法可比的性能。
文中的部分可视化效果如下:

总结
在许多汽车厂商都尝试去掉 LiDAR 传感器的当下,如何利用好成千上万无标注的图像数据,是一个重要的课题。而 OccNeRF 给我们带来了一个很有价值的尝试。

原文链接:https://mp.weixin.qq.com/s/UiYEeauAGVtT0c5SB2tHEA



