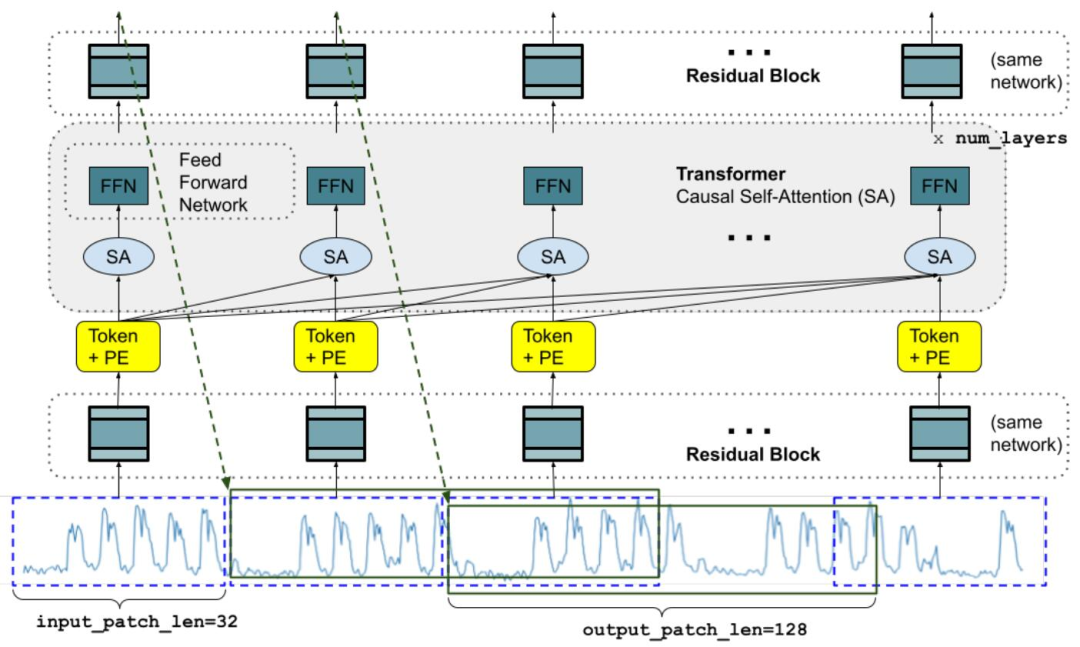
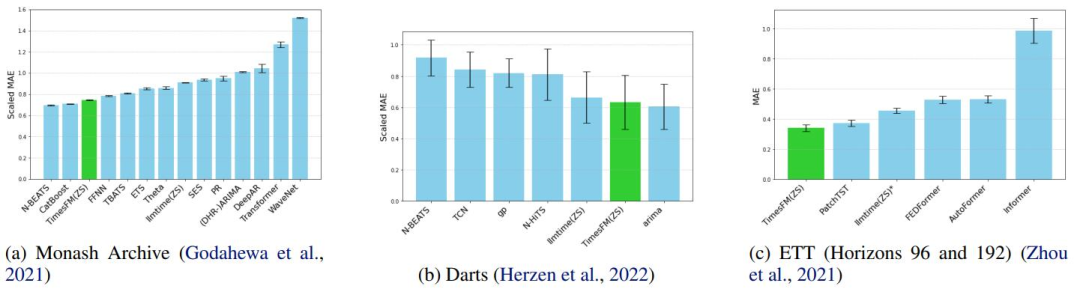
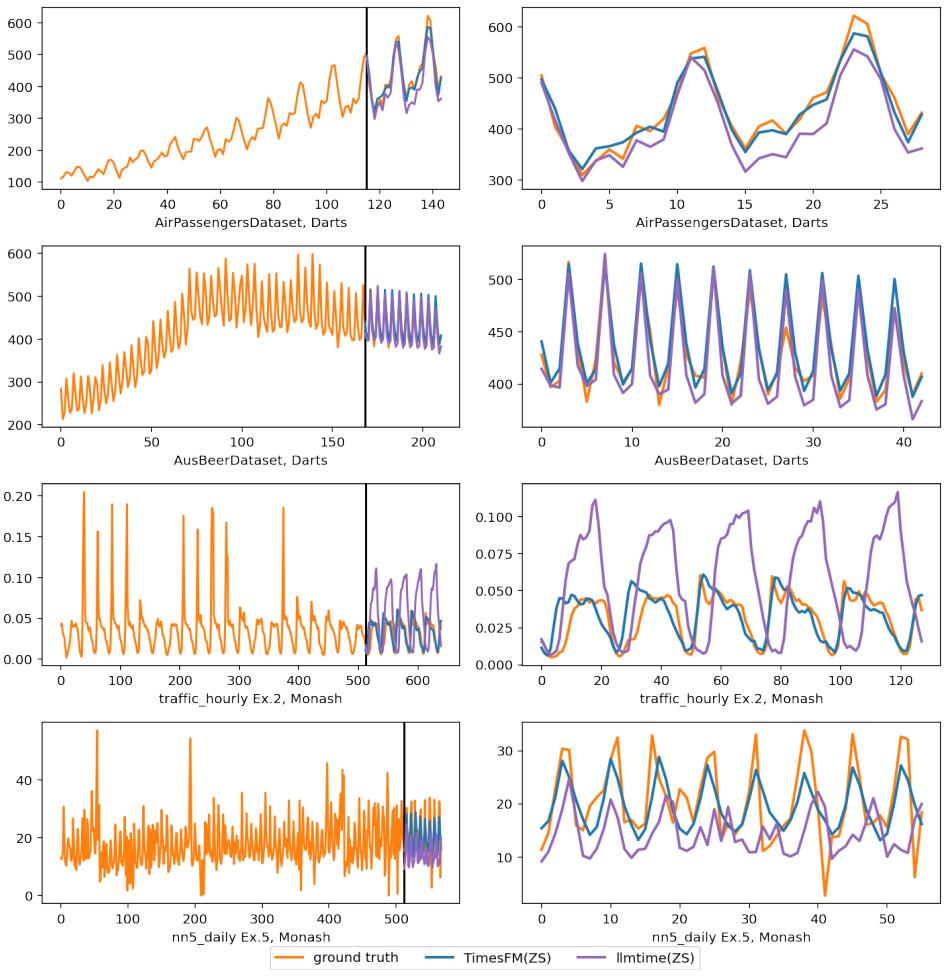
产品中心
软件问答
产品教程
时间:2024-11-29
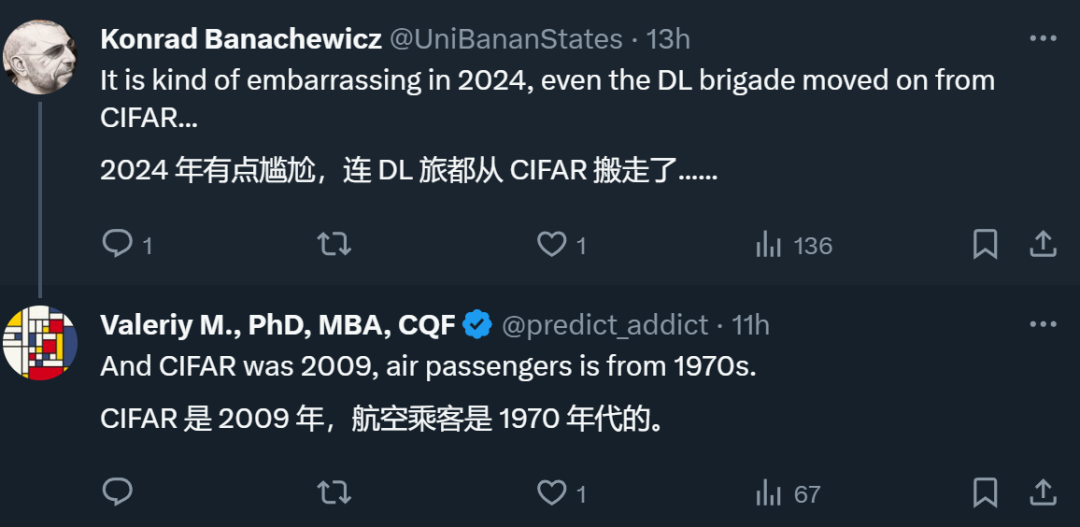
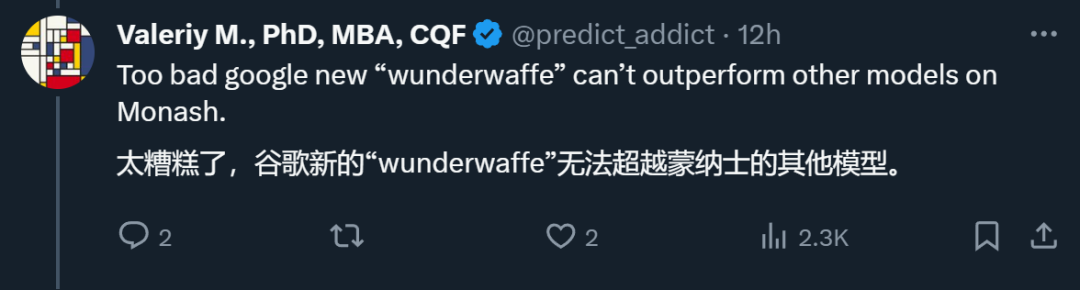
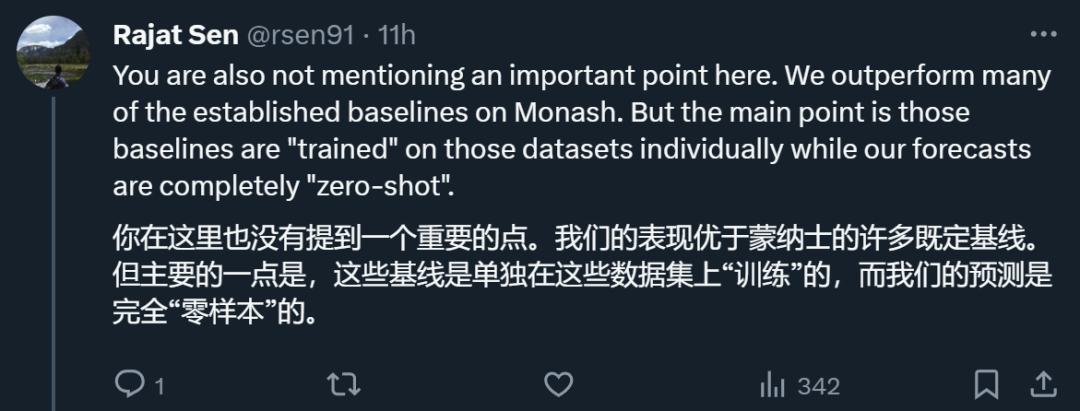
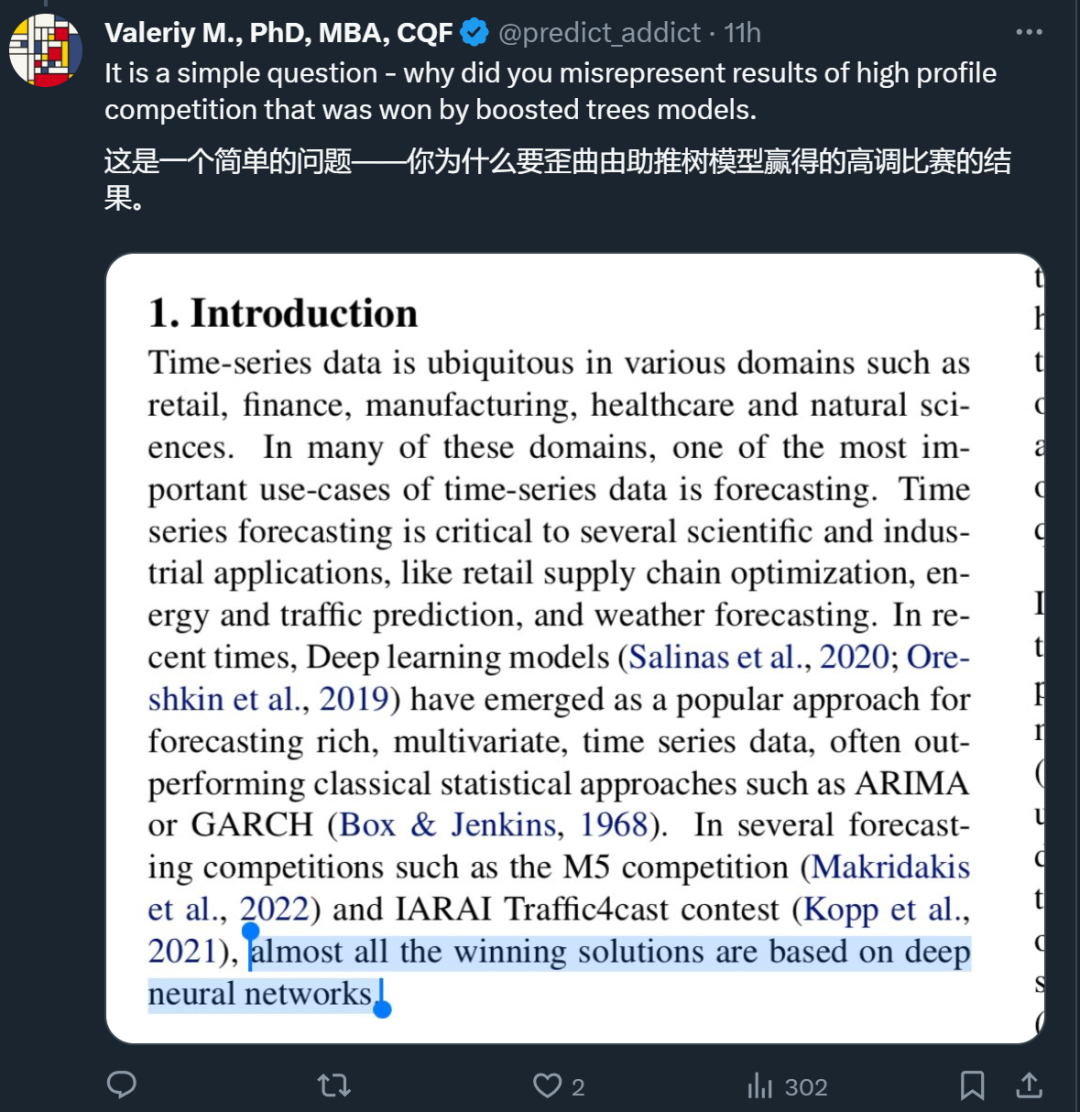
照箭画靶,跑分自设标准?
¥150.00 ¥150.00
¥198.00 ¥198.00
¥189.00 ¥189.00
¥1788.00 ¥8200.00
奈飞继续进军古装悬疑剧市场,收购《大唐狄公案》和《长安十二时辰》后发布新作品
50 架波音 737 MAX 将进行修复工作,因供应商错误钻孔位置
供应链的自动化实现与机器人及人工智能的关系
UC伯克利Meta展示音频生成真实人像的AI技术,精确驱动面部和肢体动作!
全新中型轿车比亚迪秦L在工信部车展上炫耀其引领潮流的地位