智能体也要有“规范手册”!
一项名为MetaGPT的研究,通过对智能体角色进行明确分工,并要求多个智能体在协作中采用统一规范的“交流格式”等方法,让智能体性能大增。
目前,这项研究在GitHub上已狂揽33.6k星,并在深度学习顶会ICLR 2024上被收录为Oral论文。
总的来说,MetaGPT是模仿人类的分工协作方式,将各种任务的标准操作流程编码为智能体的“规范手册”,不同角色的智能体负责不同的专业任务。
比如产品经理角色可以使用网络搜索工具,而工程师角色可以执行代码:
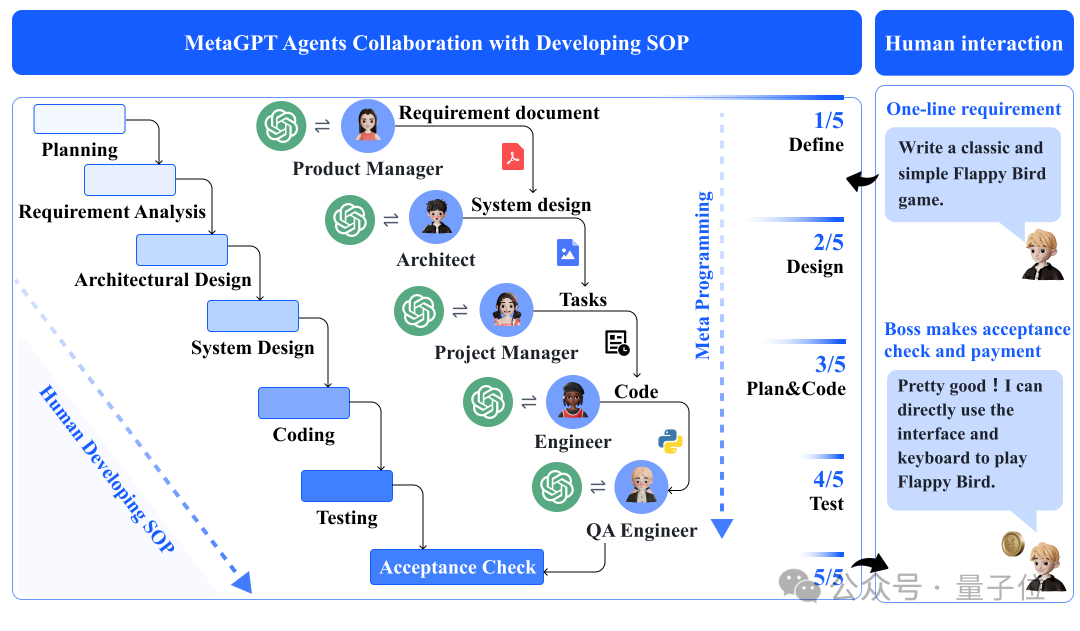
由此多智能体协作完成任务。
研究人员为智能体们设置了一个“消息共享群”,智能体可以自由查看其他智能体发送的相关消息。
经测试,使用这种方法,在代码补全任务的公开数据集HumanEval和MBPP上,MetaGPT分别取得了85.9%和87.7%的新SOTA。
目前这项工作已开源,在全网受到不少网友关注:
MetaGPT长啥样?
这项研究由DeepWisdom团队联合KAUST AI中心、厦门大学、CUHK(SZ)、南京大学、UPenn以及UCB等众多高校机构的学者共同提出。

随着大模型能力的不断提升,基于大模型的智能体来解决各种任务在学术界和工业界的兴趣日益增长。
值得注意的是,对于采用多个智能体协作解决特定领域问题的研究仍处于早期阶段。现有研究主要集中在通过角色扮演机制和通信拓扑设定来增强任务理解和推理决策能力。尽管取得了一定进展,但这些方法仍然依赖于直接的对话形式,缺乏对智能体行为的标准规范和约束。
近期的一些工作也指出,基于对话形式的多智能体系统可能面临信息不一致、歧义以及可能的无效重复和无限循环等问题。
相较之下,人类工作流程中的标准操作流程(SOPs)不仅明确定义了参与角色的分工和拓扑结构,还建立了角色产出结果的标准规范。
研究表明,明确定义的SOPs可以提高任务执行的一致性和准确性,确保最终结果符合规定的质量标准。因此,为解决多智能体协作中的挑战,研究人员设计了基于大模型的智能体元编程框架MetaGPT。
MetaGPT要求智能体以专家形式参与协作,并按要求生成结构化的输出,例如高质量的需求文档、架构设计图和流程图等。
结构化的输出对于单个智能体即是更高层次的思维链(Chain-of-Thought),对于下游角色则是语义清晰、目标明确的上下文(Context)。
在MetaGPT的框架中,研究人员将SOPs的概念对齐至角色专业化、通信协议设计以及迭代式的可执行反馈设计。
角色专业化
通过明确定义的角色分工,复杂的工作得以分解为更小、更具体的任务。
如下图所示,不同专业的角色,初始化为不同的目标和约束,以及不同的专业技能。如产品经理角色可以使用网络搜索工具,而工程师角色可以执行代码。与此同时,每个角色都默认遵循ReAct的行为模式。
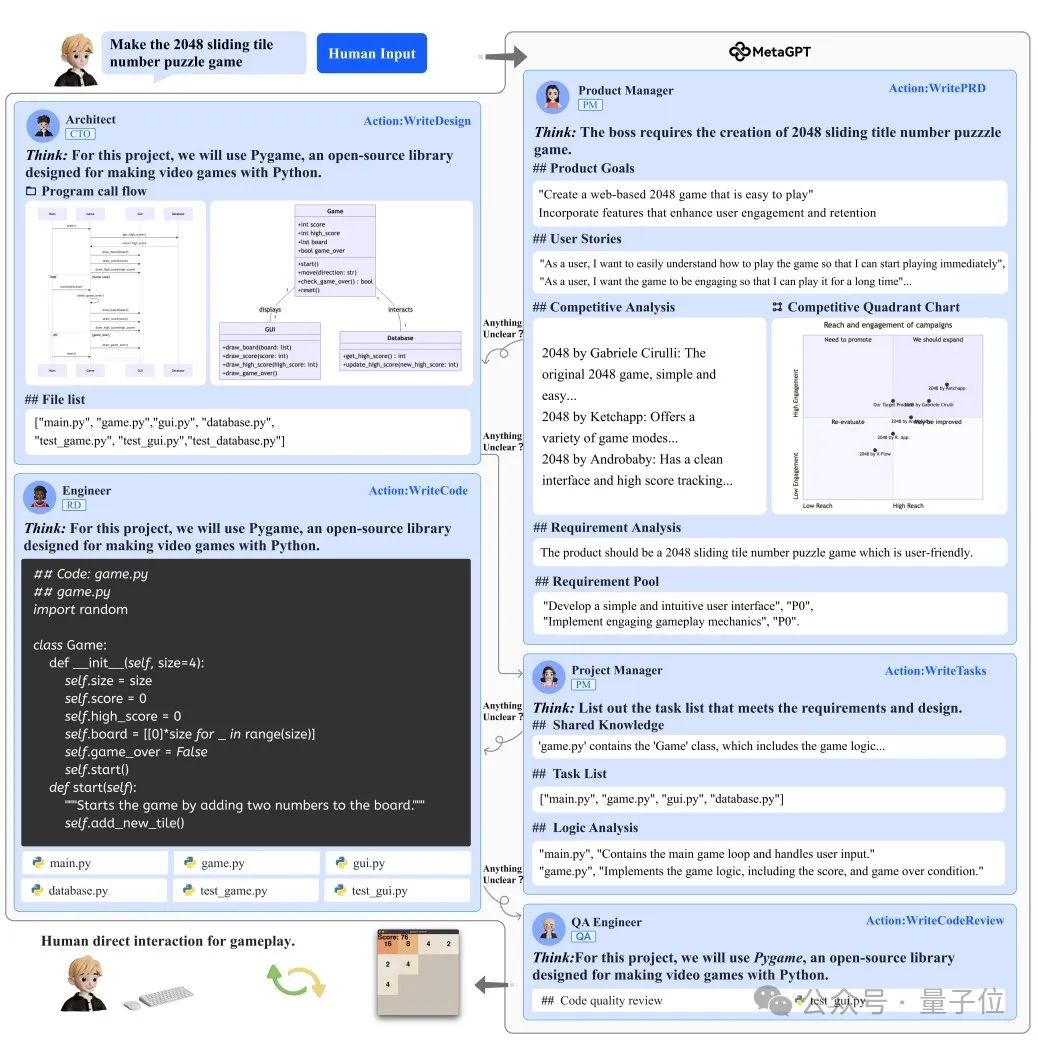
角色专业化使得每个智能体能够专注于其领域内的具体任务,从而提升了大模型的输出质量。
对于软件开发而言,通过角色的流转,这种分工更巧妙地完成了从自然语言到编程语言的对齐。论文中的角色消融实验进一步证明了这一部分的效果。
通信协议设计
在实际应用中,自然语言虽然具备语义的丰富性,但由于其非结构化的特性,在消息传递过程中常常会导致信息的歪曲甚至重要内容的丢失。
为解决这一问题,作者约束智能体以结构化的输出(包括文档和图表)参与协作,来提高信息的清晰度和完整性。为验证这一设计,作者设计了多种软件开发任务,通过生成代码的可执行性以及生产力指标强调结构化输出在协作中的关键性。
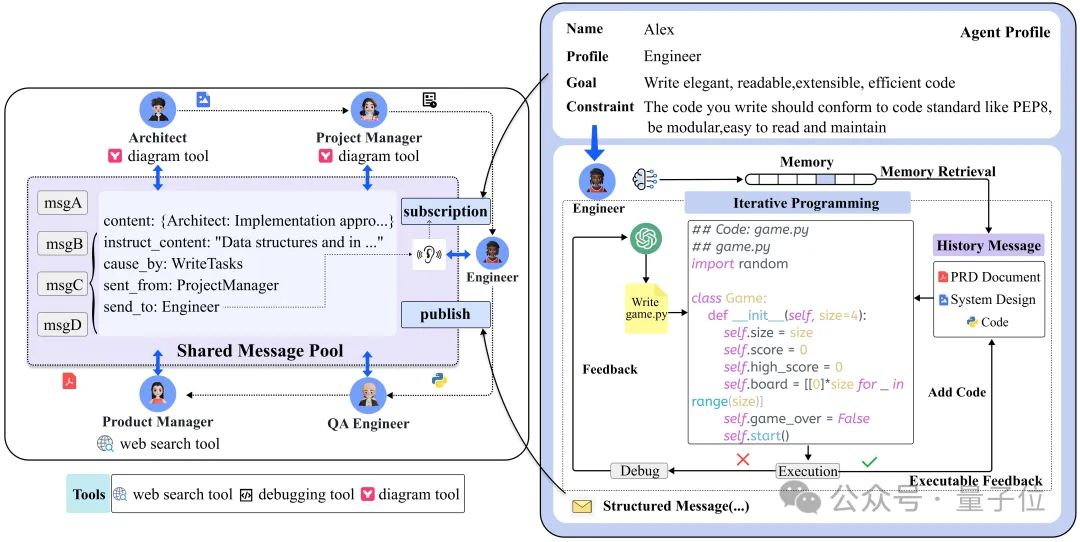
在多智能体协作过程中,为提高通信效率,MetaGPT引入了基于消息共享的发布-订阅机制(Publish-Subscribe Mechanism)。
如上图所示,共享消息池允许直接交换消息,任何智能体都可以透明地访问来自其他智能体的消息,无需询问并等待响应。订阅机制使智能体更倾向于接收与自我任务相关的信息,避免分心于不相关的细节。同时,每个智能体可直接从共享消息池中检索所需信息,形成自我记忆。
可执行反馈
智能体根据环境反馈进行自我优化和主动更新,是智能体具备自主意识的表现。
在软件开发任务上,MetaGPT为工程师的智能体设计了可执行反馈机制,以进行代码质量自动优化。
具体而言,工程师编写并执行相应的单元测试用例,通过观察到的执行结果,递归地进行决策和自我提示,实现自动debug。这种设计-测试-反馈的迭代过程持续进行,直到单元测试通过或达到最大重试次数。
多个基准测试新SOTA
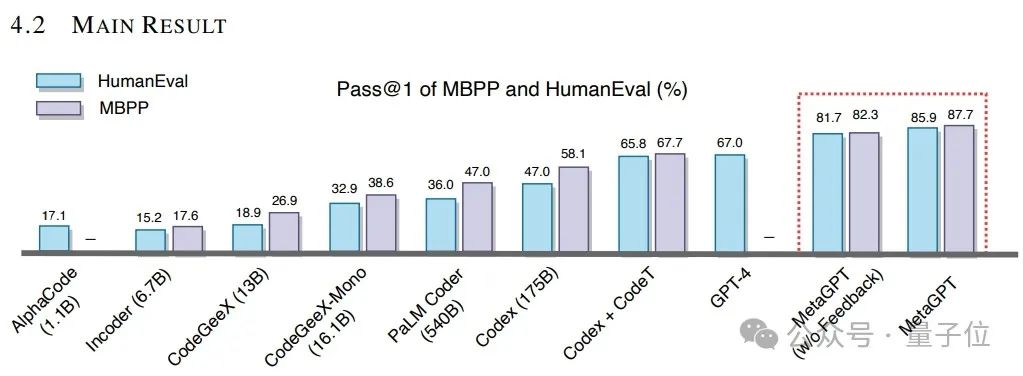
在代码生成能力上,研究人员采用了两个公开基准数据集:HumanEval和MBPP,并报告Pass@1指标。
另外,他们还收集了涵盖70个典型软件开发任务(如迷你游戏、数据可视化、图像处理等)的数据集SoftwareDev,并进行了多个智能体开源框架的对比,对多个软件开发任务的可执行性和生产效率上进行了统计分析和定性说明。
如下图所示,MetaGPT在HumanEval和MBPP基准测试中均优于之前的方法,分别达到了85.9%和87.7%。相比于GPT-4的结果,MetaGPT在HumanEval数据集上相对提升了28.2%,而加入可执行反馈机制分别在HumanEval和MBPP上提升了4.2%和5.4%。
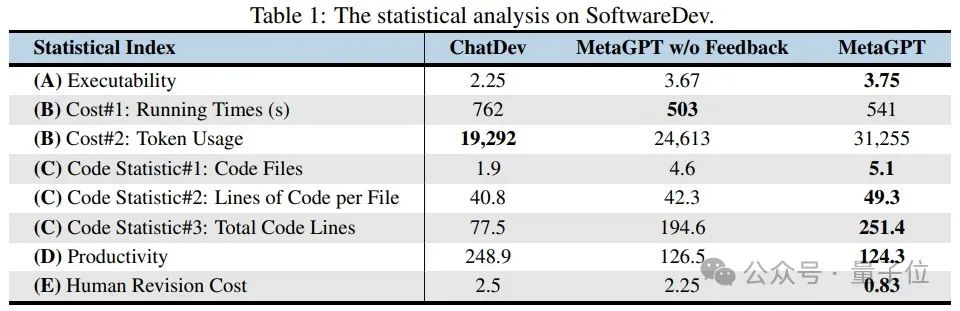
在具有挑战性的SoftwareDev数据集上,MetaGPT在可执行性上的得分为3.75,非常接近4,而所需的运行时间较短(503秒);生成的代码行数相对基线框架增加了2.24倍,而单位代码行数所消耗的token数下降了50%。
这些结果突显了多智能体协作过程中SOPs带来的效率提升。
MetaGPT在软件开发任务中的高可执行性和相对较短的运行时间表明了其在实际应用中的实用性和效率。
聚焦在软件开发领域,研究人员提供了不同智能体框架能力的定性对比。
他们发现,MetaGPT不仅具备多种模态的文件生成能力,也是目前众多框架中唯一完整覆盖了真实世界中软件开发过程的开源框架。

总的来说,MetaGPT是一个新颖的多智能体框架,结合元编程思想,嵌入SOPs来增强大模型在多智能体协作上的能力。
通过角色专业化,工作流管理和灵活的消息机制,使其成为通用性和可移植性高的多智能体框架。
结合迭代式的反馈机制,MetaGPT在多个基准测试上取得SOTA性能。
结合人类社会实践的SOPs,启发了未来对于多智能体社会的研究和探索,也可视为对基于大模型的多智能体框架进行调节的早期尝试。
论文链接:https://arxiv.org/abs/2308.00352
代码链接:https://github.com/geekan/MetaGPT



