机器学习在各个领域都取得了巨大的成功,并且不断涌现出大量优质的机器学习模型。然而,对于普通用户来说,要找到适合自己任务的模型并不容易,更不用说从零开始构建新模型了。为了解决这个问题,南京大学周志华教授提出了一种名为「学件」的范式,通过模型加上规约的思路构建了一个学件市场(现称为学件基座系统),使用户能够统一地选择和部署模型来满足自己的需求。现在,学件范式迎来了首个开源的基础平台,名为北冥坞(Beimingwu)。这个平台将为用户提供一个丰富的模型库和部署工具,使得使用和定制机器学习模型变得更加简单和高效。通过北冥坞,用户可以更好地利用机器学习的力量,解决各种实际问题。

在经典的机器学习范式中,为了从头训练高性能模型,需要大量的高质量数据、专家经验和计算资源,这无疑是一项耗时耗力且成本高昂的任务。此外,复用已有模型也存在一些问题。例如,很难将训练好的特定模型适应不同的环境,而在逐步改进训练好的模型过程中可能会出现灾难性遗忘的情况。因此,我们需要寻找一种更加高效和灵活的方法来应对这些挑战。
数据隐私和所有权问题不仅阻碍了开发者之间共享经验,也限制了大型模型在数据敏感场景中的应用能力。研究通常将重点放在这些问题上,但实践中往往同时出现并相互影响。
在自然语言处理和计算机视觉领域,主流大模型发展范式虽然取得了显著的成就,但是仍未解决一些重要问题。这些问题包括计划外任务和场景的无限性、环境的不断变化性、灾难性遗忘、高资源需求、隐私问题、本地化部署需求以及个性化和定制化的要求。因此,为每个潜在任务构建对应的大模型是不切实际的解决方案。这些挑战需要我们寻找新的方法和策略来应对,例如采用更加灵活和可定制的模型架构,利用迁移学习和增量学习等技术来适应不同任务和环境的变化。只有通过综合多种方法和策略,我们才能更好地解决这些复杂的问题。
为了解决机器学习任务,南京大学周志华教授在2016年提出了学件(learnware)概念。他基于学件创建了一个全新的范式,并提出了学件基座(dock)系统作为基础平台。这个系统的目标是统一容纳全球开发者提交的机器学习模型,并根据潜在用户的任务需求来利用模型能力解决新任务。这一创新为机器学习领域带来了新的可能性和机会。
学件范式的核心设计是这样的:对于来自不同任务的高质量模型,学件是一个格式统一的基础单元。学件包含了模型本身以及以某种表示描述模型特性的规约。开发者可以自由提交模型,学件坞系统将协助产生规约,并将学件存放在学件坞中。在这个过程中,开发者无需向学件坞泄露自己的训练数据。将来,用户可以向学件基座系统提交需求,通过查找和复用学件来解决自己的机器学习任务,而无需向学件系统泄露自有数据。这种设计使得模型共享和任务解决变得更加高效、便捷和隐私安全。
而为了建立学件范式的初步科研平台,周志华教授团队近日构建了北冥坞(Beimingwu),它是第一个开源的、用于未来学件范式研究的学件基座系统。相关论文已经公布,足足有 37 页。
在技术层面上,北冥坞系统通过可扩展的系统和引擎架构设计以及广泛的工程实现和优化,为未来的学件相关算法和系统研究打下了基础。此外,系统还集成了全流程基线算法,并构建了算法基础评估场景。这些特点不仅使得系统能够为学件提供支持,还为托管大量学件和建立学件生态系统提供了可能性。

论文标题:Beimingwu: A Learnware Dock System
论文地址:https://arxiv.org/pdf/2401.14427.pdf
北冥坞主页:https://bmwu.cloud/
北冥坞开源仓库:https://www.gitlink.org.cn/beimingwu/beimingwu
核心引擎开源仓库:https://www.gitlink.org.cn/beimingwu/learnware
在本文中,研究者的贡献可总结如下:
基于学件范式,简化了用户解决新任务的模型开发:做到了数据高效、无需专家知识和不泄露原始数据;
提出了完整统一且可扩展的系统引擎架构设计;
开发了具有统一用户接口的开源学件基座系统;
用于不同场景的全流程基线算法实现和评估。
学件范式概览
学件范式由周志华教授团队于 2016 年提出,并在 2024 年的论文《Learnware: small models do big》中进行总结并进一步设计。该范式的简化流程如下图 1 所示:对于任何类型和结构的高质量机器学习模型,它们的开发者或所有者可以自发地将训练好的模型提交到学件基座系统(以往称为学件市场)中。
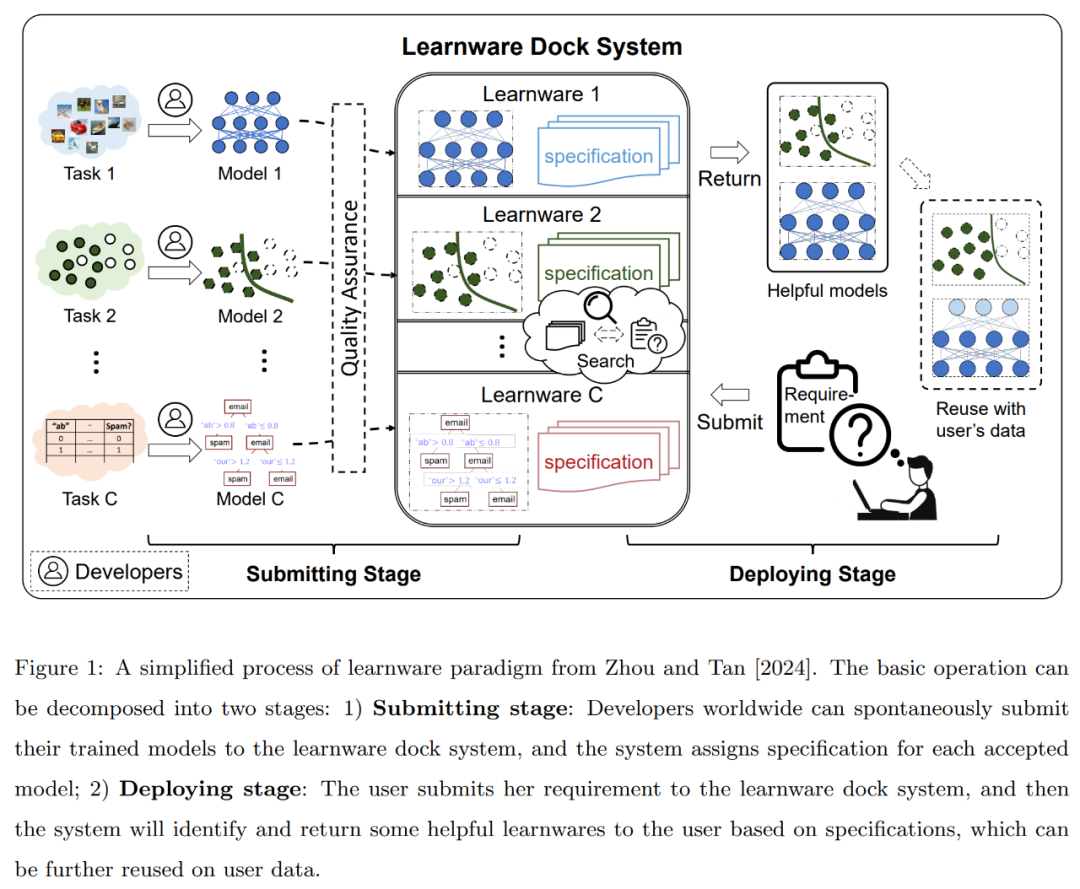
正如前文所介绍,学件范式提出建立一个学件基座系统,来统一容纳、组织和利用表现良好的已有模型,从而统一地利用来自所有社区的努力来解决新的用户任务,并有可能同时解决大家关心的一些重大问题,包括了训练数据和训练技巧缺乏、灾难性遗忘、难以实现持续学习、数据隐私或专有化、开放世界中计划外的新任务、重复浪费训练导致的碳排放等。
最近,学件范式及其核心思想受到了越来越多的关注。但关键问题和主要的挑战在于:考虑到学件基座系统可以容纳数千甚至数百万个模型,如何识别和选择对新用户任务最有帮助的一个或一组学件?显然,直接将用户数据提交到系统中进行试验的成本高昂,并且会泄露用户的原始数据。
学件范式的核心设计在于规约,最近研究主要基于缩略核均值嵌入(reduced kernel mean embedding, RKME)规约。
虽然现有的理论和实证分析研究已经证明了基于规约的学件识别的有效性,但学件基座系统的实现仍然缺失并面临巨大的挑战,需要基于规约的全新架构设计来应对多样化的真实世界任务和模型,并根据用户的任务需求统一地查搜和复用大量的学件。
研究者构建了首个学件基座系统 —— 北冥坞,对包括提交、可用性测试、组织、管理、识别、部署和学件复用在内的全流程提供了支持。
利用北冥坞解决学习任务
基于学件范式的首次系统实现,北冥坞显著简化了为新任务构建机器学习模型的过程。现在,我们可以按照学件范式的流程来构建模型。并且受益于统一的学件结构、统一的架构设计和统一的用户接口,北冥坞中所有提交的模型实现了统一识别和复用。
令人兴奋的是,给定一个新的用户任务,如果北冥坞拥有能够解决这项任务的学件,则只需要几行代码,用户就可以轻松地获得并部署其中的高质量模型,不需要大量数据和专家知识,也不会泄露自己的原始数据。
下图 2 为利用北冥坞解决学习任务的代码示例。

下图 3 展示了使用北冥坞的整个工作流程,包括统计规约生成、学件识别、加载和复用。基于工程实现和统一的接口设计,每一步都可以通过一行关键代码来实现。

研究者表示,在解决学习任务时,基于北冥坞,使用学件范式的模型开发流程具有以下几点显著优势:
不需要大量的数据和计算资源;
不需要大量的机器学习专业知识;
为多样化模型提供统一、简单的本地部署;
隐私保护:不泄露用户的原始数据。
目前,北冥坞初期仅拥有 1100 个在开源数据集上构建的学件,覆盖的场景不多,处理大量特定和未见过场景的能力依然有限。基于可扩展的架构设计,北冥坞可以作为学件范式的研究平台,为学件相关研究提供便捷的算法实现和实验设计。
与此同时,依赖基础实现和可扩展架构支撑,不断提交的学件和不断提升的算法将不断增强系统解决任务的能力,并增强系统复用现有训练良好的模型以解决超出开发者原始目标的新任务的能力。未来,学件基座系统的持续演进使其能够响应越来越多的用户任务,而不会发生灾难性遗忘,并自然地实现终身学习。
北冥坞设计
论文第 4 节介绍了北冥坞系统的设计。如图 4 所示,整个系统包括四个层次:学件存储、系统引擎、系统后台和用户界面。这一节首先介绍了每一层的概况,然后介绍了基于规约设计的系统核心引擎,最后介绍了系统中实现的算法。
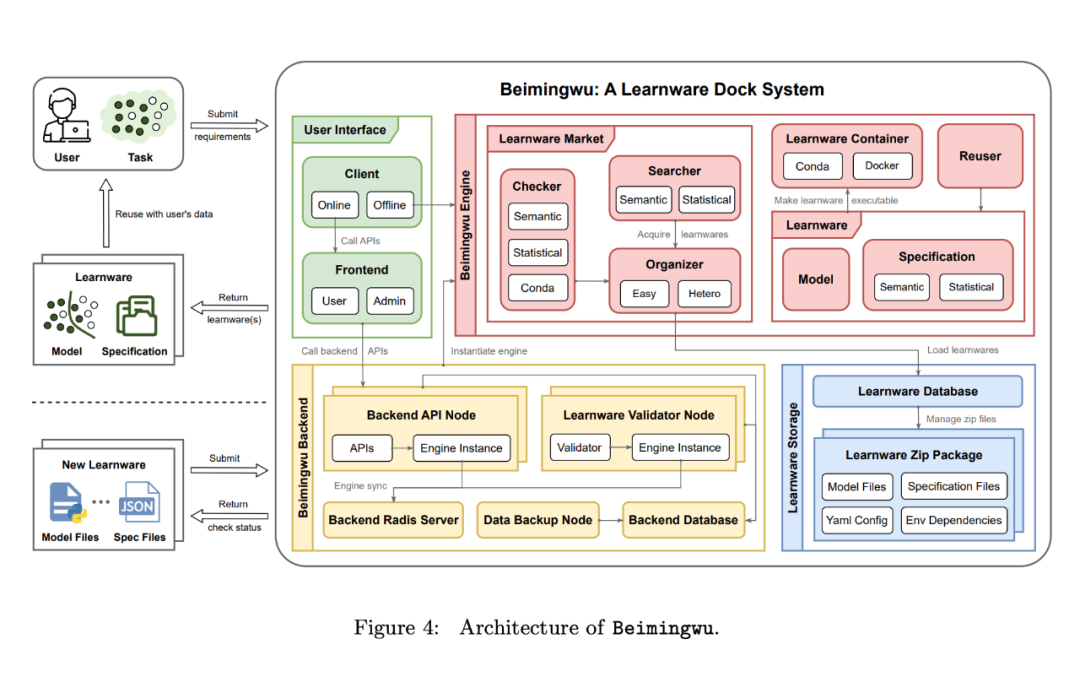
首先看下每一层的概况:
学件存储层。在北冥坞,学件以压缩包的形式存储。这些压缩包主要包括四类文件:模型文件、规约文件、模型执行环境依赖文件和学件配置文件。
这些学件压缩包由学件数据库集中管理。数据库中的学件表存储了关键信息,包括学件 ID、存储路径和学件状态(如未验证和已验证)。该数据库为北冥坞后续核心引擎访问学件信息提供了统一的接口。
此外,该数据库可使用 SQLite(适用于开发和实验环境中的简易设置)或 PostgreSQL(推荐用于生产环境中的稳定部署)构建,两者使用相同的接口。
核心引擎层。为了保持北冥坞的简洁性和结构性,作者将核心组件和算法从大量的工程细节中分离出来。这些抽取出来的组件现在可以作为学件 python 包使用,它是北冥坞的核心引擎。
作为系统内核,该引擎涵盖了学件范式中的所有流程,包括学件的提交、可用性测试、组织、识别、部署和复用。它独立于后台和前台运行,为学件相关任务和研究实验提供全面的算法接口。
此外,规约是引擎的核心组件,从语义和统计角度表征各个模型,连接着学件系统中各个重要组件。除了开发者提交模型时生成的规约外,引擎还能利用系统知识为学件生成新的系统规约,从而加强学件的管理并进一步表征其能力。
现有的模型管理平台,如 Hugging Face,仅被动地收集和托管模型,让用户自行决定模型的能力和与任务的相关性,与之相比,北冥坞通过其引擎,以全新的系统架构主动管理学件。这种主动管理不仅限于收集和存储,该系统根据规约组织学件,可以根据用户任务需求匹配相关学件,并提供相应的学件复用和部署方法。
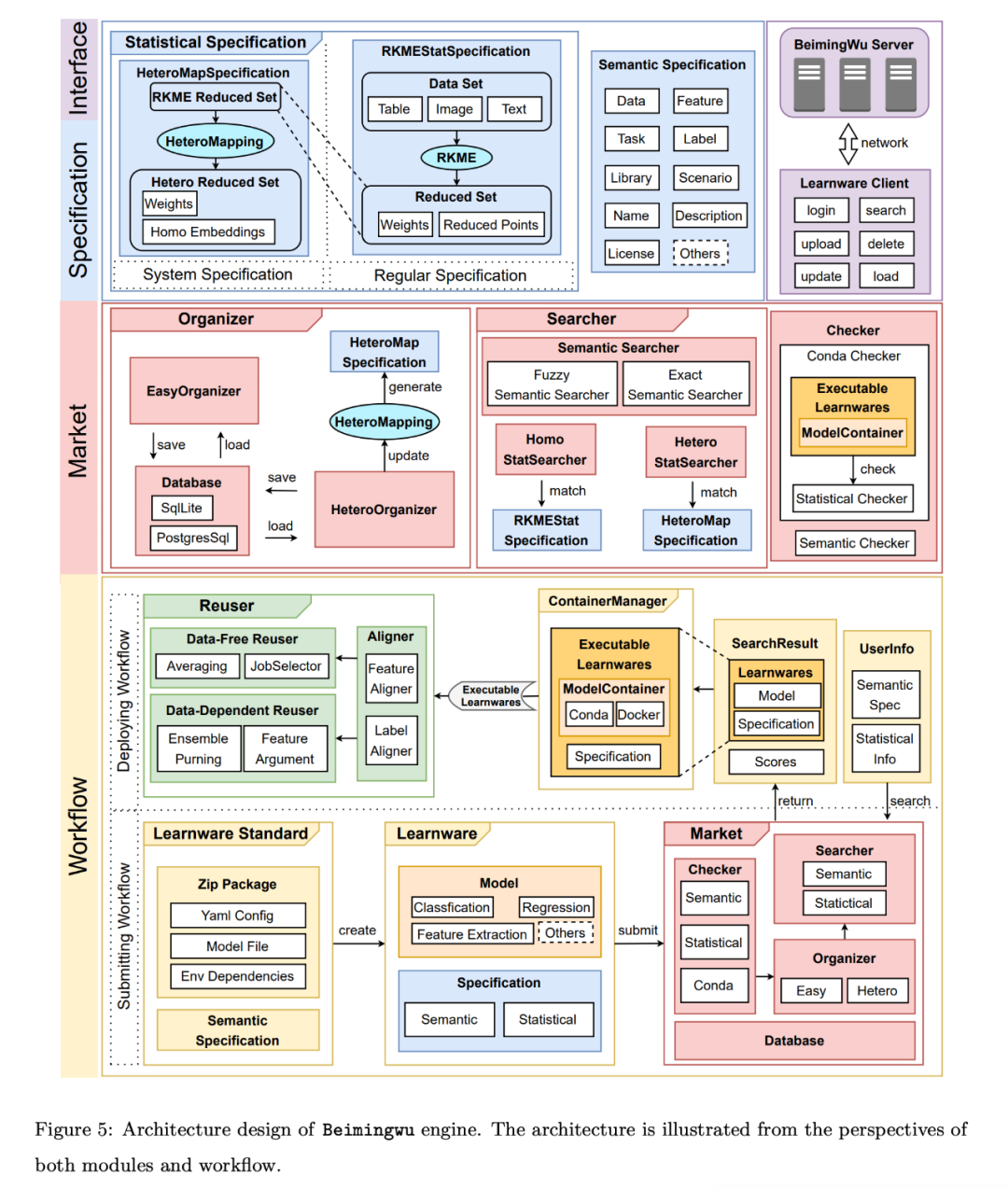
核心模块设计如下图:
系统后台层。为了使北冥坞实现稳定部署,作者在核心引擎层的基础上开发了系统后台。通过多个模块的设计和大量的工程开发,北冥坞目前已具备在线稳定部署的能力,为前端和客户端提供了统一的后台应用程序接口。
为确保系统高效稳定运行,作者在系统后台层进行了多项工程优化,包括异步学件验证、跨多后端节点的高并发性、界面级权限管理、后台数据库读写分离、系统数据自动备份。
用户接口层。为方便北冥坞用户使用,作者开发了相应的用户接口层,包括基于网络的浏览器前端和命令行客户端。
基于 web 的前端同时提供用户和管理员版本,提供各种用户交互和系统管理页面。此外,它还支持多节点部署,以便顺利访问北冥坞系统。
命令行客户端与学件 python 包集成在一起。通过调用相应接口,用户可以通过前端调用后台在线 API,访问学件相关模块和算法。
实验评估
在第 5 节中,作者构建了各种类型的基础实验场景,以评估在表格、图像和文本数据上进行规约生成、学件识别和复用的基准算法。
表格数据实验
在各种表格数据集上,作者首先评估了从学件系统中识别和复用与用户任务具有相同特征空间的学件的性能。此外,由于表格任务通常来自不同的特征空间,作者还对来自不同特征空间的学件的识别和复用进行了评估。
同质案例
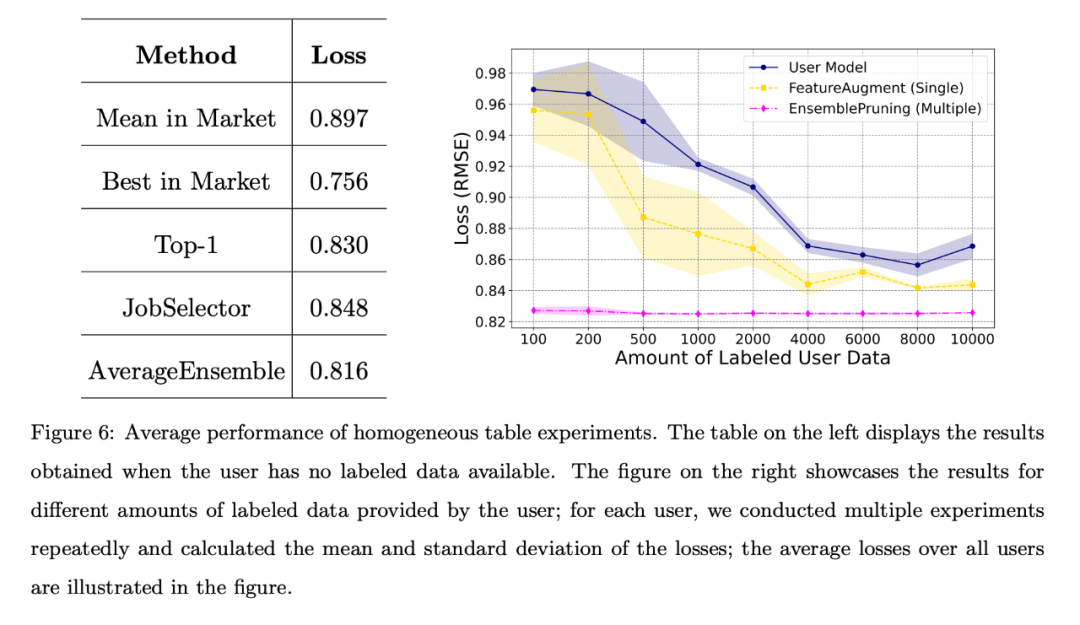
在同质案例中,PFS 数据集中的 53 个商店充当 53 个独立用户。每个商店利用自己的测试数据作为用户任务数据,并采用统一的特征工程方法。这些用户随后可以在基座系统上查搜与其任务具有相同特征空间的同质学件。
当用户没有标注数据或标注数据量有限时,作者对不同的基准算法进行了比较,所有用户的平均损失如图 6 所示。左表显示,无数据方法比从市场上随机选择和部署一个学件要好得多;右图表明,当用户的训练数据有限时,识别并复用单个或多个学件比用户自训练的模型性能更优。
异构案例
根据市场上学件与用户任务的相似性,异构案例可进一步分为不同的特征工程和不同的任务场景。
不同的特征工程场景:图 7 左显示的结果表明,即使用户缺乏标注数据,系统中的学件也能表现出很强的性能,尤其是复用多个学件的 AverageEnsemble 方法。
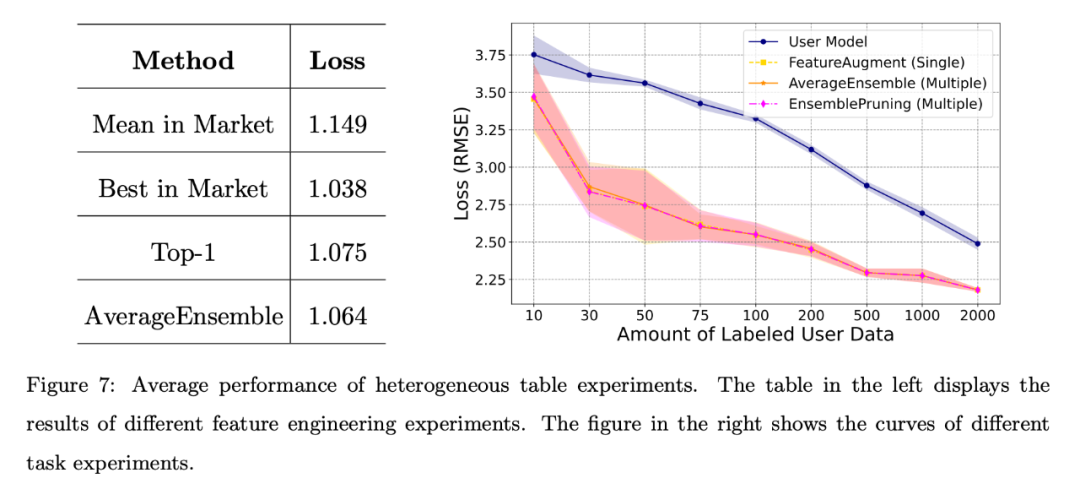
不同的任务场景。图 7 右显示了用户自训练模型和几种学件复用方法的损失曲线。很明显,异构学件在用户标注数据量有限的情况下实验验证是有益的,有助于更好地与用户的特征空间进行对齐。
图像和文本数据实验
此外,作者在图像数据集上对系统进行了基础的评估。
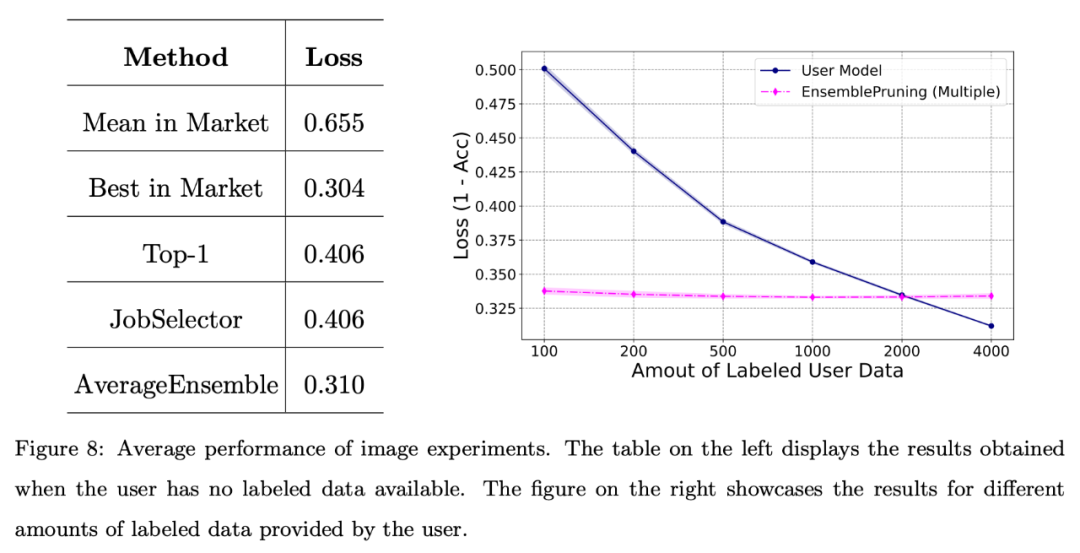
图 8 显示,当用户面临标注数据稀缺或仅拥有有限数量的数据(少于 2000 个实例)时,利用学件基座系统可以产生良好的性能。
最后,作者在基准的文本数据集上对系统进行了基础评估。通过统一的特征提取器进行特征空间对齐。
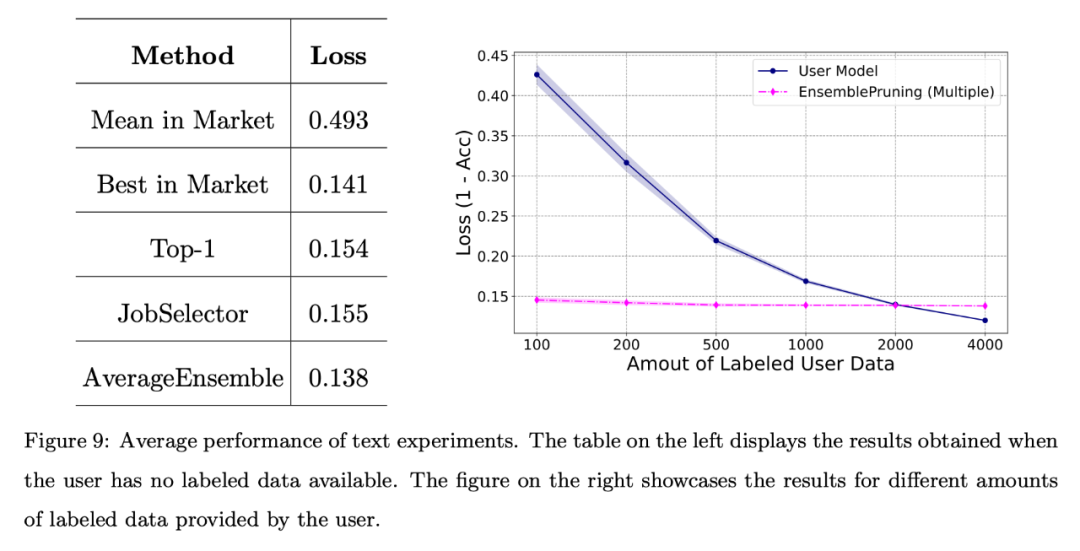
结果如图 9 所示,同样地,即使在没有提供标注数据的情况下,通过学件识别和复用所获得的性能也能与系统中最好的学件相媲美。此外,与从头开始训练模型相比,利用学件基座系统可以减少约 2000 个样本。
更多研究细节,可参考原论文。



