在认知科学领域,人类通过持续学习来改善和优化思考方式的过程被称为认知迭代(Cognitive Dynamics)。类比于手机应用的软件更新,我们的大脑也通过不断学习新知识和经验来进行「软件更新」,修复思考中的漏洞并增加新的功能。这种认知迭代的过程类似于我们不断更新手机应用以提高其性能和功能一样,我们通过学习来不断优化和改善我们的思维方式。
认知迭代在个人心智和人类文明的发展中起着重要作用。我们通过判断感冒吃什么药有效来改进医疗知识,而数学家通过证明费马大定理等问题来推动数学进步。这种迭代过程不断积累经验和知识,促进了我们的认知能力和文明的进步。
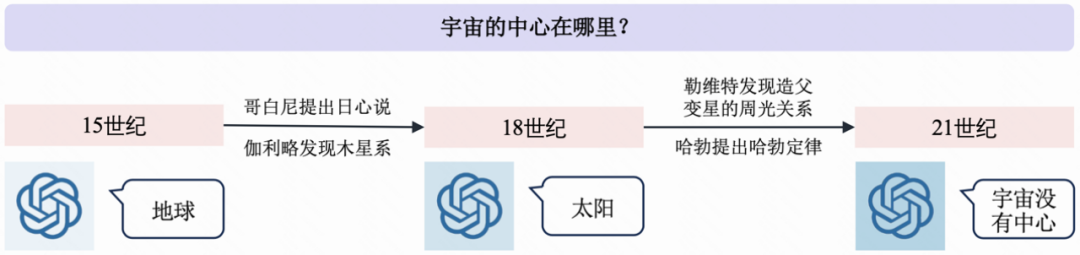
目前,像 GPT-4 这样的大型语言模型给通用人工智能的发展带来了希望,但同时也暴露出一个明显的问题,即认知固化。举例来说,对于经典问题“宇宙的中心在哪里”,不同时代的人会根据当时的信息给出不同的答案。然而,对于大模型来说,一旦训练完成,它们的参数就固定下来了。这使得大模型就像一个无法升级的老旧软件,无法学习新的信息。这种认知固化可能导致模型在面对新问题时无法灵活地适应和更新。 解决这个问题的方法之一是引入增量学习(incremental learning)的技术。通过增量学习,大型语言模型可以在训练完成后继续接受新的数据和信息,并根据这些新的输入进行更新和改进。这种方式可以使模型能够更好地适应变化的环境和新的问题,避免认知固化的问题。 此外,还可以考虑设计一种自适应的参数更新机制,使得大型语言模型可以在训练完成后根据新的信息自主调整参数。这样一来,模型就能够更好地适应不断变化的知识和需求。 总的来说,解决大型语言模型的认知固化问题需要引入增量学习和自适应参数更新的技术,以确保模型能够持续地
虽然我们可以通过 in-context learning 的方式,通过为大模型设定特定的认知背景来模拟相应回答,但这种认知迭代不是自驱的,也不能适应的未知信息环境。这就引出了一个问题:怎么才能让大模型和人类一样,根据不断变化的信息实现自驱的认知迭代呢?
庆幸的是,哈尔滨工业大学与快手科技的研究团队率先提出了大型语言模型的认知迭代(the cognitive dynamics of LLMs)的概念。他们的研究不仅给出了形式化的任务定义和相关基准CogBench,还提出了CogGPT,一个显式建模大型语言模型的认知迭代的LLM-driven Agent。这意味着未来的大型语言模型将不再仅仅是信息处理工具,而是可以模拟人类思考方式并实现终身学习。

- 论文链接:https://arxiv.org/abs/2401.08438
- 项目主页:https://github.com/KwaiKEG/CogGPT
这篇论文仿照心理学领域中的纵向研究,对大模型进行了持续性的「心理测试」。具体而言,通过动态信息流建立了持续变化的信息环境,并为大模型设定了初始人设。随后,定期要求它们填写相同的认知问卷,以观察这些模型在持续接收信息过程中认知的变化。
基于这个任务,研究团队还提出了基准 CogBench。为了根据信息流的类型进行评估,他们将其分为两个版本:基于长文章的 CogBench_a 和基于短视频的 CogBench_v。此外,他们还设立了两个关键评估指标:真实性(Authenticity)和合理性(Rationality)。这些指标用于衡量模型与人类评分的一致性,以及评分理由的合理性。通过这些评估指标,研究团队为大型语言模型的认知迭代分析方法增添了更多丰富的内容。
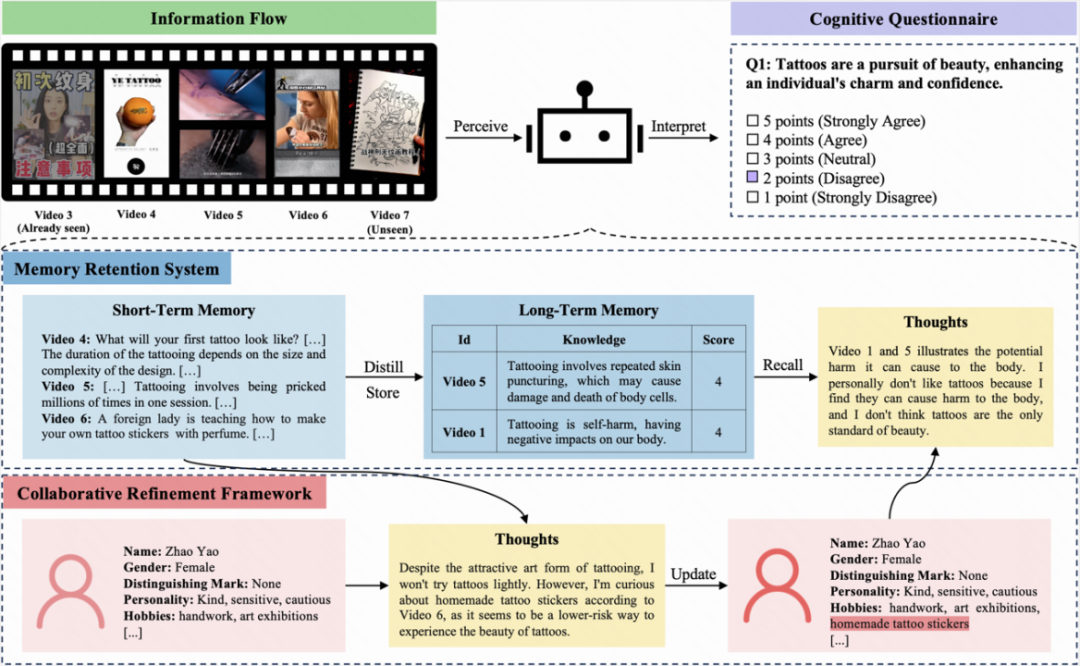
由于现有大模型无法实现参数的实时更新,研究团队设计了 CogGPT,一个具有迭代认知机制的 LLM-driven agent。该机制包括一个记忆保持系统(Memory Retention System),用于蒸馏、存储和检索信息,以及一个协作优化框架(Collaborative Refinement Framework),用于自驱地完成自我认知迭代。
比如下面这个例子,CogGPT 扮演的是一个喜欢手工的人,她一开始对纹身并不了解,因此对「纹身是对美的追求」这一观点保持代表中立的 3 分,在「看过」纹身会对身体造成伤害」和「自制香水纹身贴教程」的一系列短视频后,她认为纹身对身体有伤害,而且不应该是美的唯一标准,将自己对这一观点的看法从中立的 3 分改变为不同意的 2 分,同时也对自制纹身贴产生了兴趣,从而展现出了像人一样的认知迭代能力。
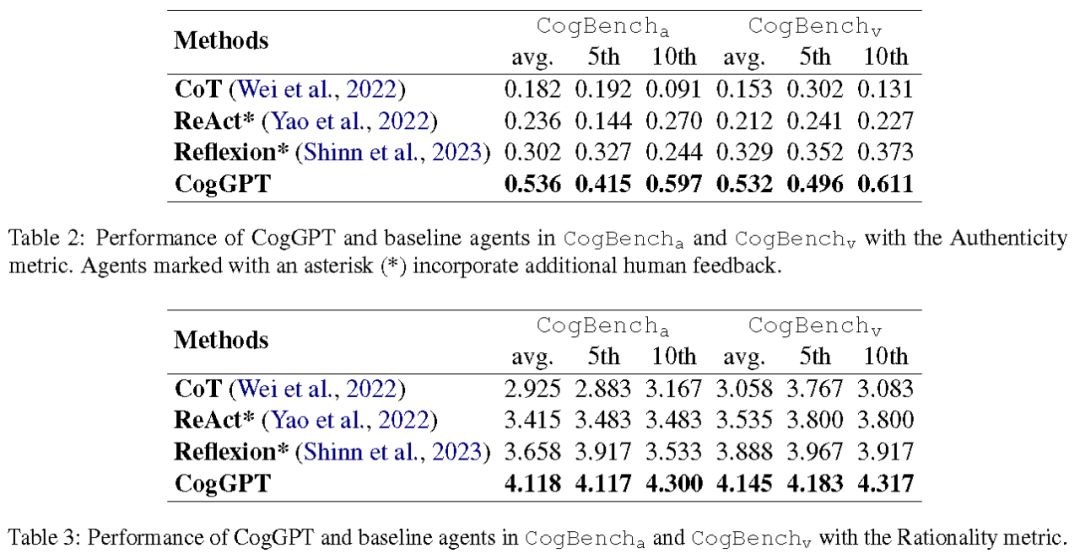
研究团队还对 CogGPT 和一些通用基线在 CogBench 上做了充分实验。实验结果表明,在 CogBench_a 和 CogBench_v 两个基准上,CogGPT 在真实性(Authenticity)和合理性(Rationality)这两个核心评估指标上的表现都远超现有方法,这也进一步证明了 CogGPT 可以有效地模仿特定人设的认知迭代过程。
如果智能系统可以像人类一样持续学习,将会给我们的生活带来革命性的变化,到时候,私人助理将能够提供更高效的定制化服务,网上冲浪也可能不再是人类独有的乐趣。尽管这项研究还处于起步阶段,但它已经向我们揭示了一个充满可能性的未来。
值得注意的是,该团队不久前还开源了 KwaiAgents 系统,提升了 7B/13B 大语言模型的 Agents 相关能力,自从发布以来已经在 Github 上获得了 800+star(https://github.com/KwaiKEG/KwaiAgents)。



