一款名为Vary-toy的“年轻人的第一个多模态大模型”来了!
模型大小不到2B,消费级显卡可训练,GTX1080ti 8G的老显卡轻松运行。
想将一份文档图片转换成Markdown格式?以往需要文本识别、布局检测和排序、公式表格处理、文本清洗等多个步骤。
现在只需一句话命令:
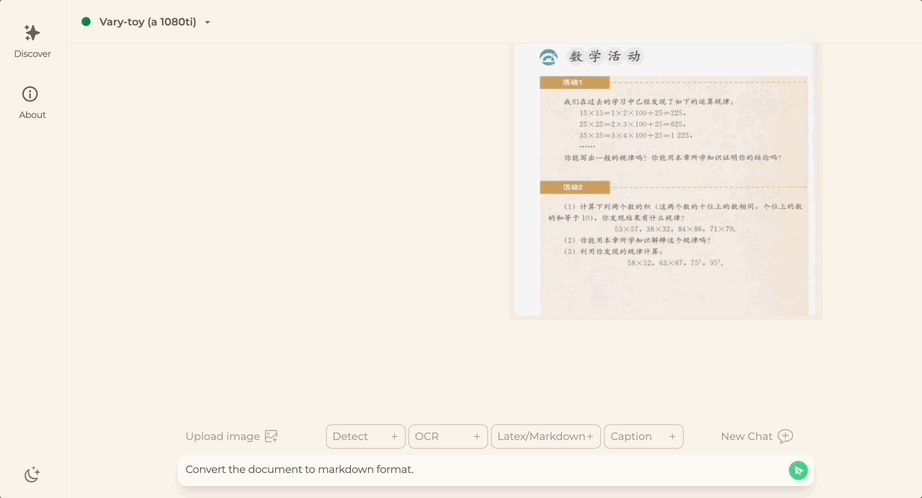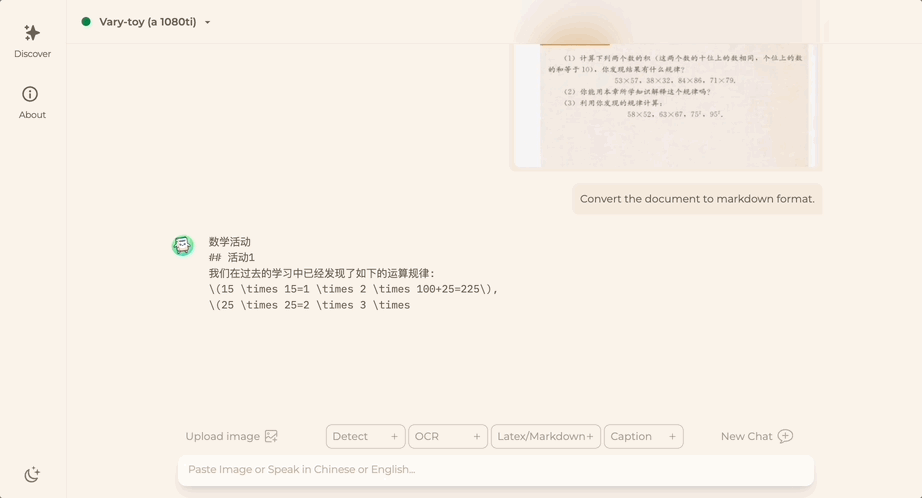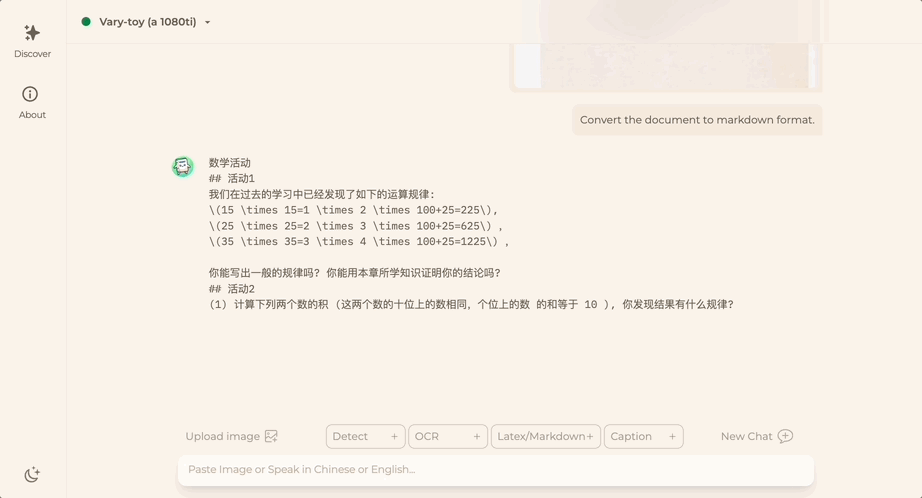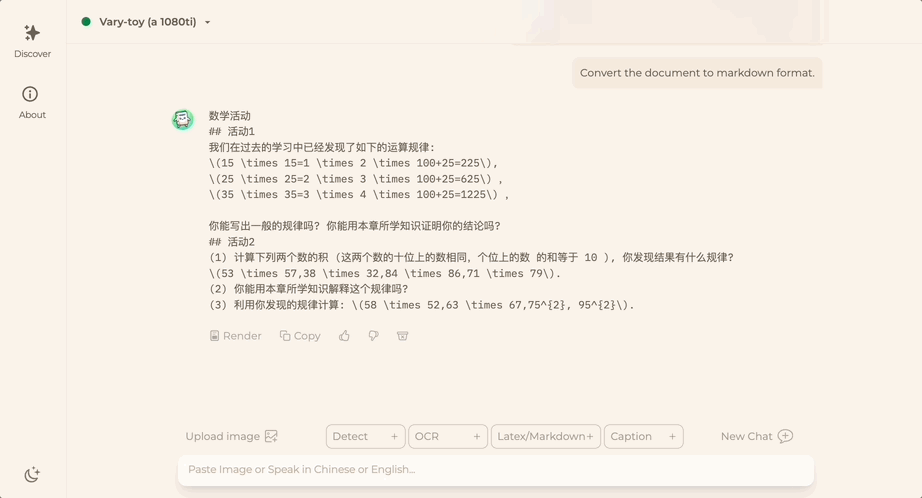
无论中英文,图片中的大段文字都能分分钟提取出来:

对一张图做对象检测,还是能给出具体坐标的那种:

这项研究由来自旷视、国科大、华中大的研究人员共同提出。
据介绍,Vary-toy虽小,但却几乎涵盖了目前LVLM(大型视觉语言模型)主流研究中的所有能力:文档OCR识别(Document OCR)、视觉定位(Visual Grounding)、图像描述(Image Caption)、视觉问答(VQA)。

现在,Vary-toy代码和模型均已开源,并有在线demo可试玩。

网友一边表示感兴趣,一边关注点在于旧·GTX1080,心情belike:

“缩小版”Vary
其实,早在去年12月Vary团队就发布了Vary的首项研究成果“Vary: Scaling up the Vision Vocabulary for Large Vision-Language Models”。
研究人员指出CLIP视觉词表在密集感知能力上的不足,并用一种简单有效的扩充词表方案给出了一种全新的OCR范式。
Vary发布后得到广泛关注,目前Github1.2k+ star,但也有不少人因为资源受限运行不了。
考虑到目前开源得很好且性能出色的“小”VLM比较少,于是该团队又新发布了号称是“年轻人的第一个多模大模型”的Vary-toy。
与Vary相比,Vary-toy除了小之外,也训练了更强的视觉词表,新的词表不再将模型局限于文档级OCR,而是给出了一个更加通用和全面的视觉词表,其不仅能做文档级OCR,还能做通用视觉目标检测。
那这究竟是如何做到的?
Vary-toy的模型结构和训练流程如下图所示,总的来说,训练共分两个阶段。
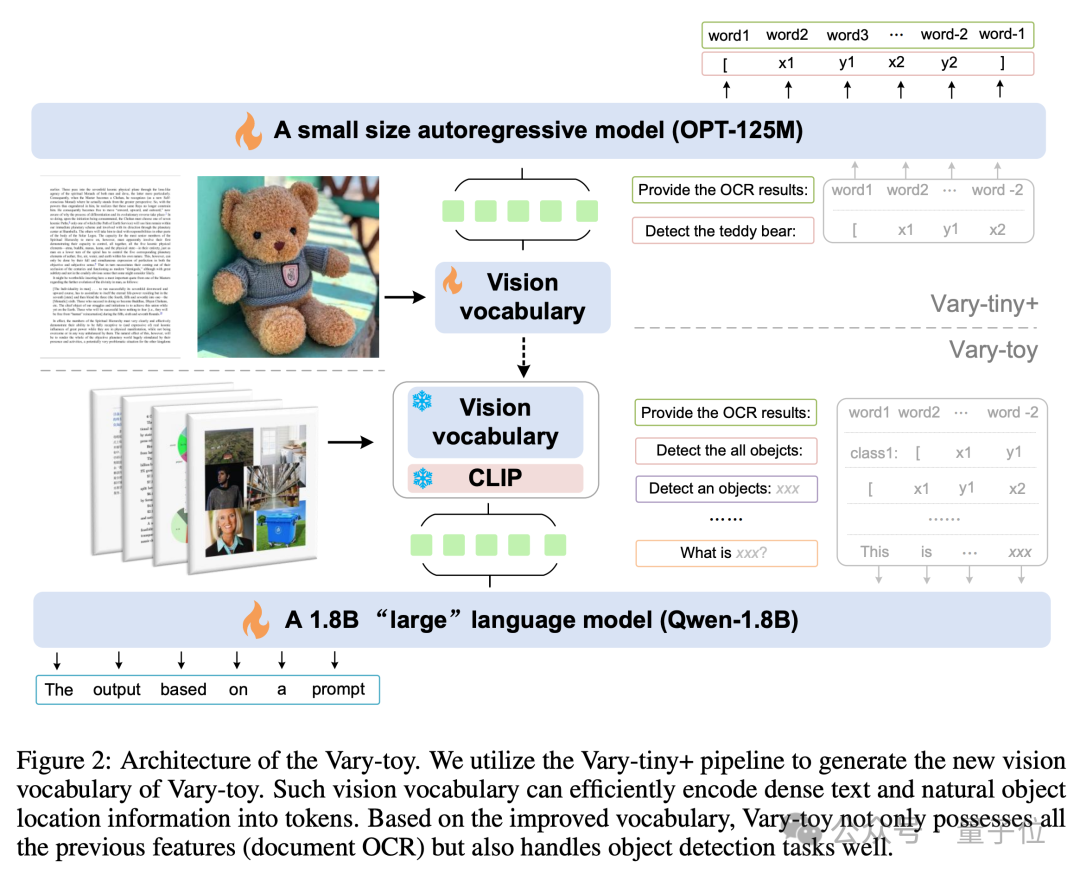
首先在第一阶段,使用Vary-tiny+结构,预训练出一个相比原版Vary更好的视觉词表,新的视觉词表解决了原Vary只用它做文档级OCR的网络容量浪费问题、以及没有充分利用到SAM预训练优势的问题。
然后在第二阶段中,将第一阶段中训好的视觉词表merge到最终结构进行multi-task training/SFT。
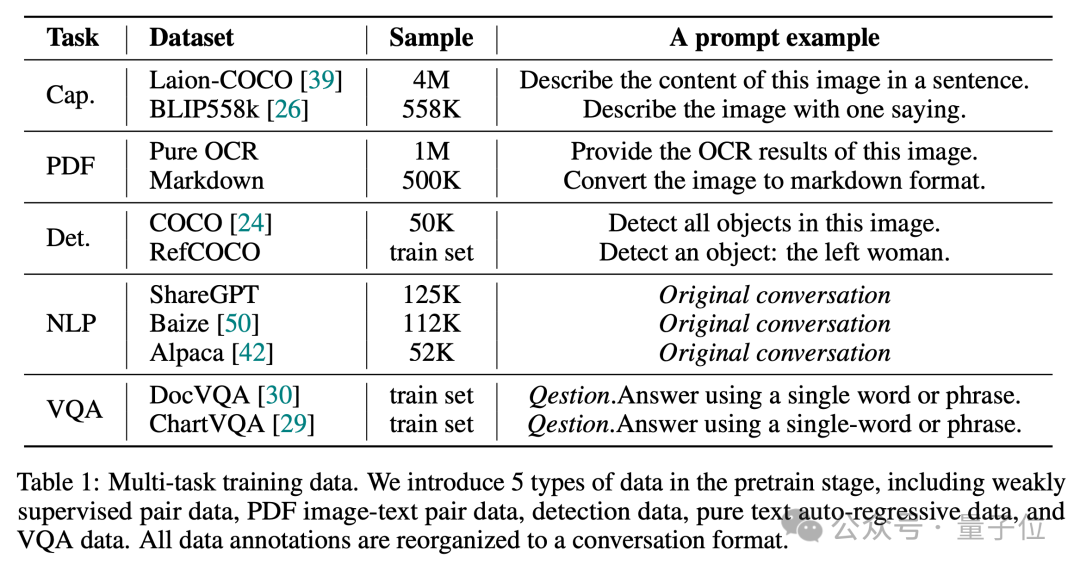
众所周知,一个好的数据配比对于产生一个能力全面的VLM是至关重要的。
因此在预训练阶段,Vary-toy使用了5种任务类型的数据构建对话,数据配比和示例prompt如下图所示:
而在SFT阶段,只使用了LLaVA-80K数据。更多的技术细节,可以查看Vary-toy的技术报告。
实验测试结果
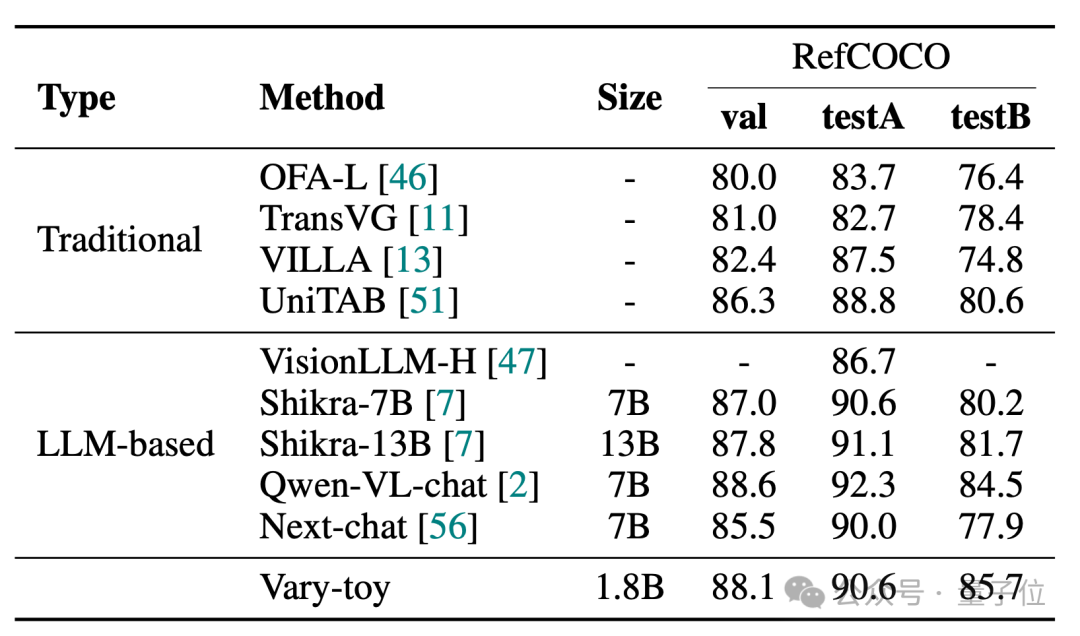
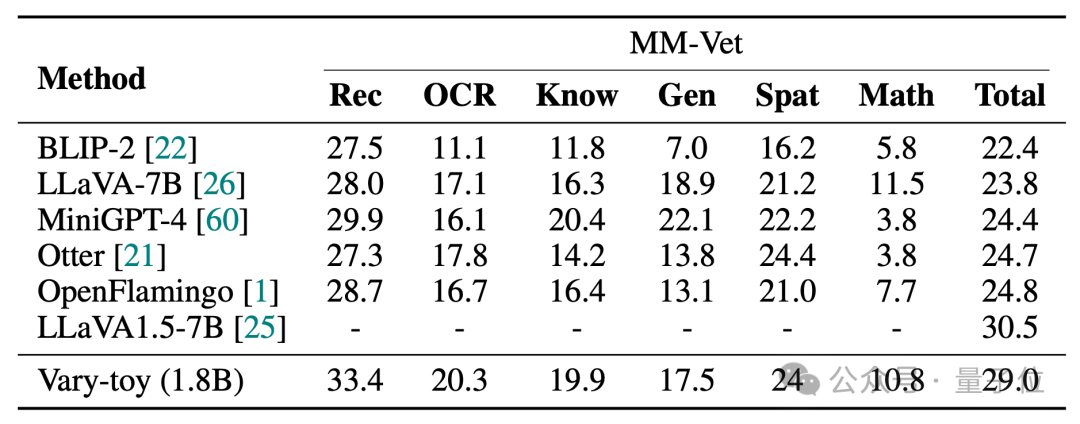
Vary-toy在DocVQA、ChartQA、RefCOCO、MMVet四个基准测试的得分如下:
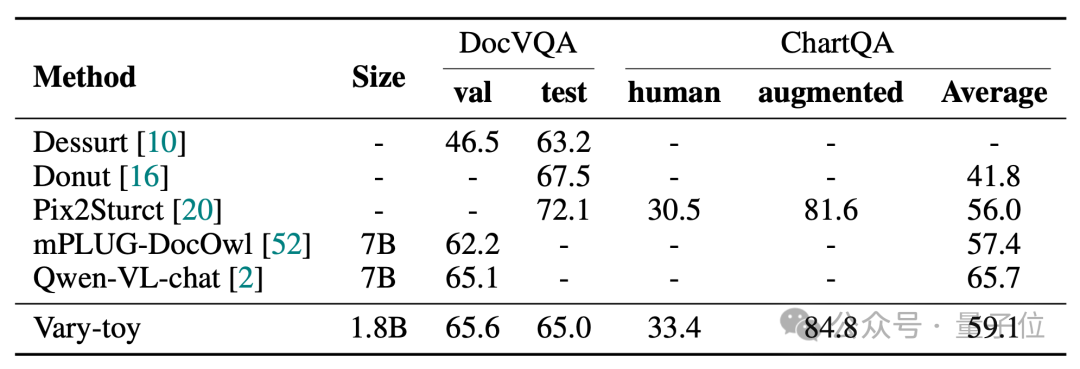
Vary-toy在DocVQA上可以达到 65.6%的ANLS,在ChartQA上达到59.1%的准确率,RefCOCO88.1%的准确率:
MMVet上可以达到29%准确率,无论是从基准测试评分上还是可视化效果上,不到2B的Vary-toy甚至能和一些流行的7B模型的性能一较高下。
项目链接:
[1]https://arxiv.org/abs/2401.12503
[3]https://varytoy.github.io/



