随着多模态大模型(LMM)的不断进步,对于评估LMM性能的需求也在增长。尤其在中文环境下,评估LMM的高级知识和推理能力变得更加重要。
在这个背景下,为了评估基本模型在中文各种任务中的专家级多模态理解能力,M-A-P 开源社区、港科大、滑铁卢大学和零一万物共同推出了 CMMMU(Chinese Massive Multi-discipline Multimodal Understanding and Reasoning)基准。该基准旨在提供一个全面的中文大规模多学科多模态理解和推理的评估平台。通过该基准,研究人员可以测试模型在多种任务中的表现,并比较其专业水平的多模态理解能力。这个联合项目的目标是促进中文多模态理解和推理领域的发展,并为相关研究提供一个标准化的参考。
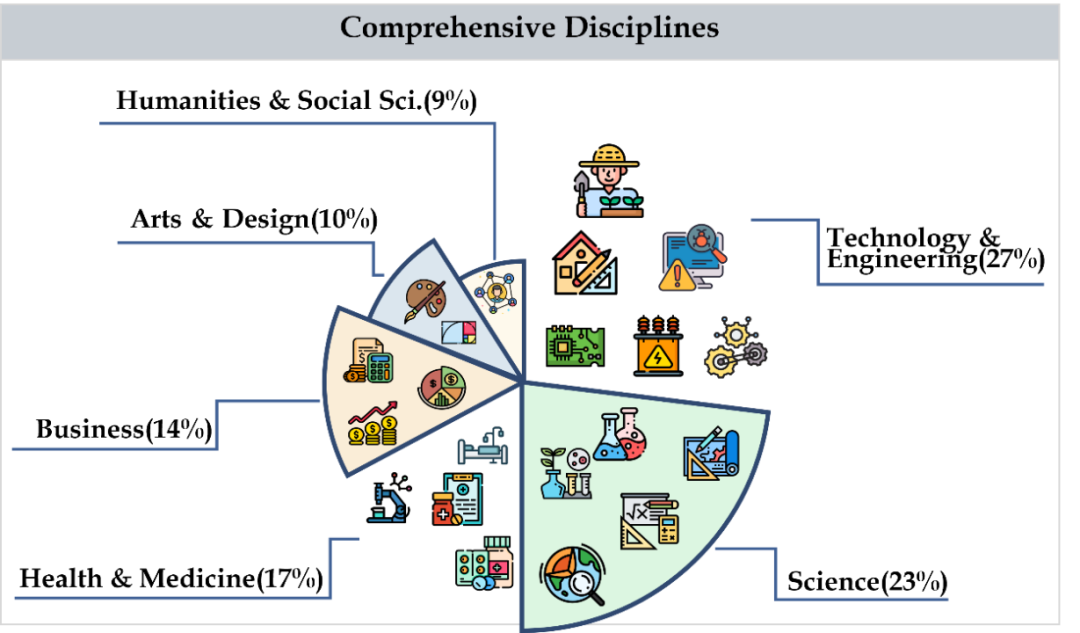
CMMMU 涵盖了六个大类学科,包括艺术、商业、健康和医学、科学、人文与社会科学、技术与工程,涉及30多个细分领域学科。下图展示了每个细分领域学科的一个题目示例。CMMMU 是第一个在中文背景下的多模态基准之一,也是少数几个考察LMM复杂理解和推理能力的多模态基准之一。

数据集构建
数据采集
数据采集分为三个阶段。首先,研究者们为每个科目收集满足版权许可要求的题目来源,包括网页或书籍。在此过程中,他们努力避免题源重复,以确保数据的多样性和准确性。 其次,研究者们将题源转发给众包标注者进行进一步的标注。所有的标注者都是拥有本科或更高学位的人员,以保证他们能够验证标注的问题和相关的解释。在标注过程中,研究者要求标注者严格遵循标注原则。例如,过滤掉那些不需要图片就能回答的问题,尽可能地过滤掉使用相同图像的问题,以及过滤掉那些不需要专家知识来回答的问题。 最后,为了平衡数据集中每个科目题目的数量,研究者们专门对问题收集较少的科目进行补充。这样做可以确保数据集的完整性和代表性,使得后续的分析和研究能够更加准确和全面。
数据集清洗
为了进一步提高CMMMU的数据质量,研究者们遵循严格的数据质量控制协议。首先,每个问题都由至少一位论文作者亲自验证。其次,为了避免数据污染问题,他们还筛选了那些几个LLM也能回答出来的问题,而不需要借助OCR技术。这些措施确保了CMMMU数据的可靠性和准确性。
数据集概览
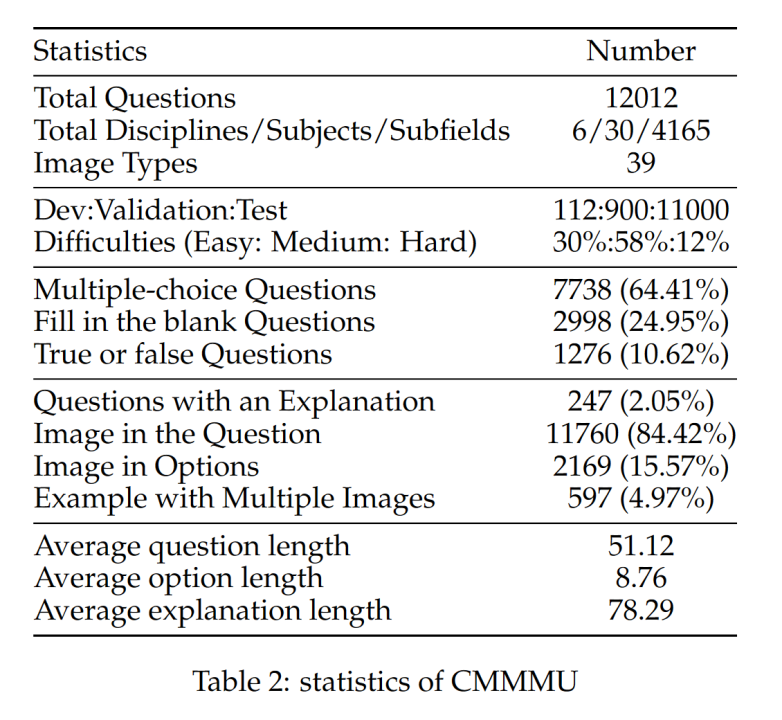
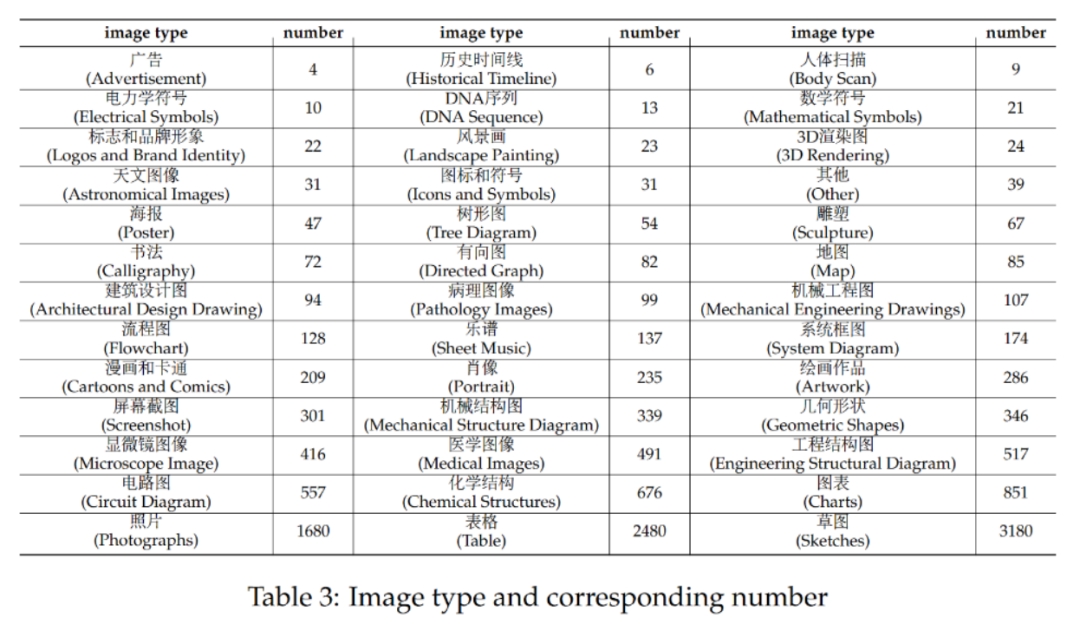
CMMMU共有12K个题目,分为少样本开发集、验证集和测试集。少样本开发集包含每个学科约5个题目,验证集有900个题目,测试集有11K个题目。题目涵盖了39种类型的图片,包括病理图、乐谱图、电路图、化学结构图等。这些题目根据逻辑难度而非智力难度被分为简单(30%)、中等(58%)和困难(12%)三个难度级别。更多题目统计信息可见表2和表3。
实验
团队测试了多种主流的中英文双语 LMM 以及几个 LLM 在 CMMMU 上的表现。其中包含了闭源和开源模型。评估过程使用 zero-shot 设置,而不是微调或者 few-shot 设置,以检查模型的原始能力。LLM 还加入了图片 OCR 结果 + text 作为输入的实验。所有的实验都是在 NVIDIA A100 图形处理器上进行的。
主要结果
表 4 展示了实验结果:
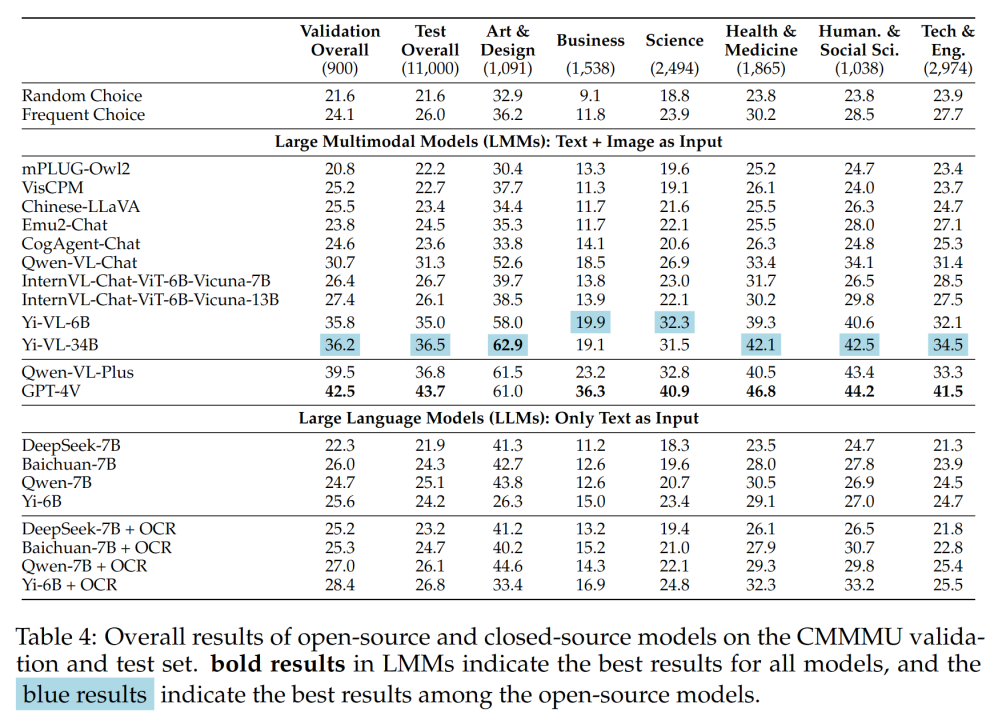
一些重要发现包括:
- CMMMU 比 MMMU 更具挑战性,且这是在 MMMU 已经非常具有挑战性的前提下。
GPT-4V 在中文语境下的准确率仅为 41.7% ,而在英语语境下的准确率为 55.7% 。这表明,现有的跨语言泛化方法甚至对于最先进的闭源 LMM 都不够好。
- 与 MMMU 相比,国内具有代表性的开源模型与 GPT-4V 之间的差距相对较小。
Qwen-VL-Chat 和 GPT-4V 在 MMMU 上的差异为 13.3% ,而 BLIP2-FLAN-T5-XXL 和 GPT-4V 在 MMMU 上的差异为 21.9% 。令人惊讶的是,Yi-VL-34B 甚至将 CMMMU 上开源双语 LMM 和 GPT-4V 之间的差距缩小到了 7.5% ,这意味着在中文环境下,开源双语 LMM 与 GPT-4V 相当,这在开源社区中是一个有希望的进步。
- 在开源社区中,追求中文专家多模态人工通用智能 (AGI) 的游戏才刚刚开始。
团队指出,除了最近发布的 Qwen-VL-Chat、 Yi-VL-6B 和 Yi-VL-34B 外,所有来自开源社区的双语 LMM 只能达到与 CMMMU 的frequent choice 相当的精度。
对不同题目难度和题型的分析
- 不同题目类型
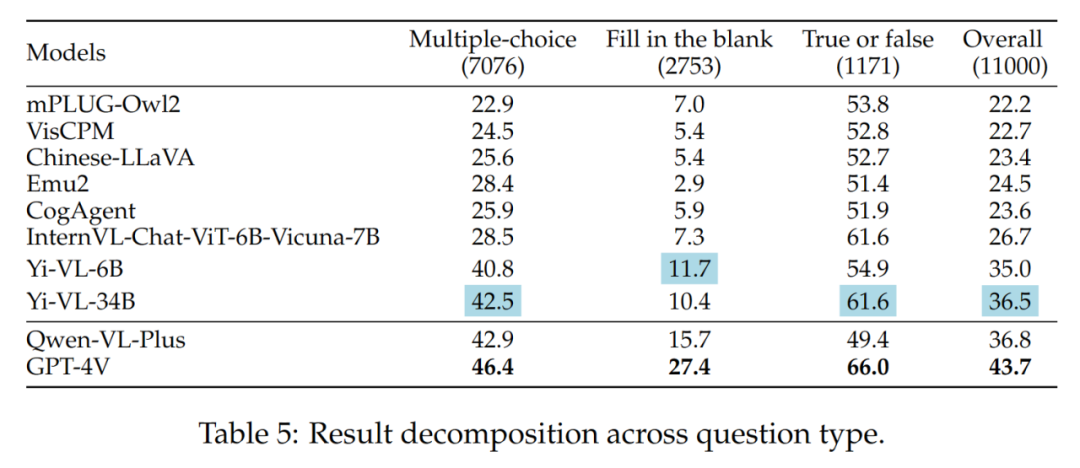
Yi-VL 系列、 Qwen-VL-Plus 和 GPT-4V 之间的差异主要还是因为它们回答选择题的能力不同。
不同题目类型的结果如表 5 所示:
- 不同题目难度
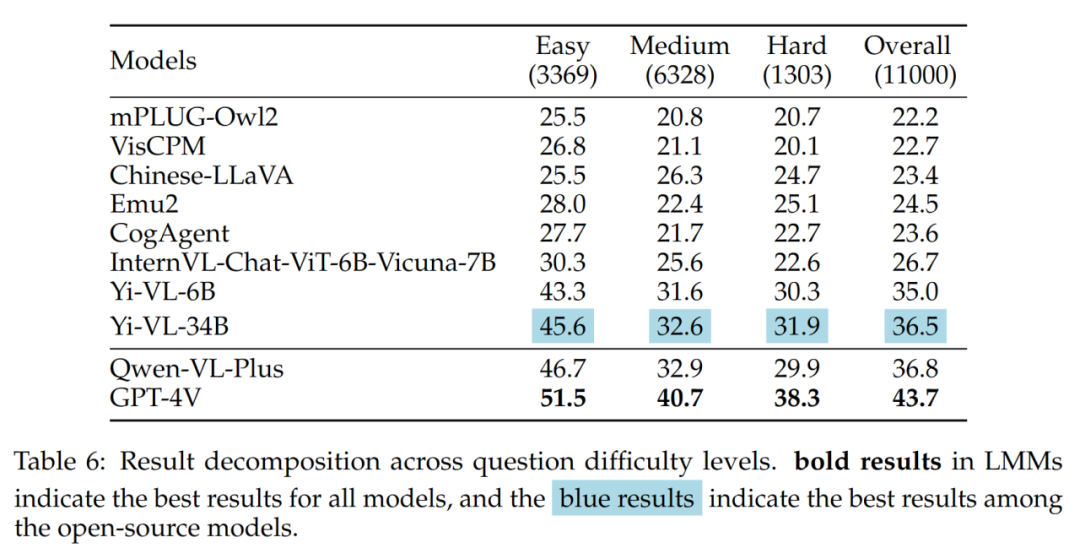
结果中值得注意的是,最好的开源 LMM (即 Yi-VL-34B) 和 GPT-4V 在面对中等和困难的问题时存在较大的差距。这进一步有力地证明,开源 LMM 和 GPT-4V 之间的关键差异在于在复杂条件下的计算和推理能力。
不同题目难度的结果如表 6 所示:
错误分析
研究者们仔细分析了 GPT-4V 的错误答案。如下图所示,错误的主要类型有感知错误、缺乏知识、推理错误、拒绝回答和注释错误。分析这些错误类型是理解当前 LMM 的能力和局限性的关键,也可以指导未来设计和培训模型的改进。
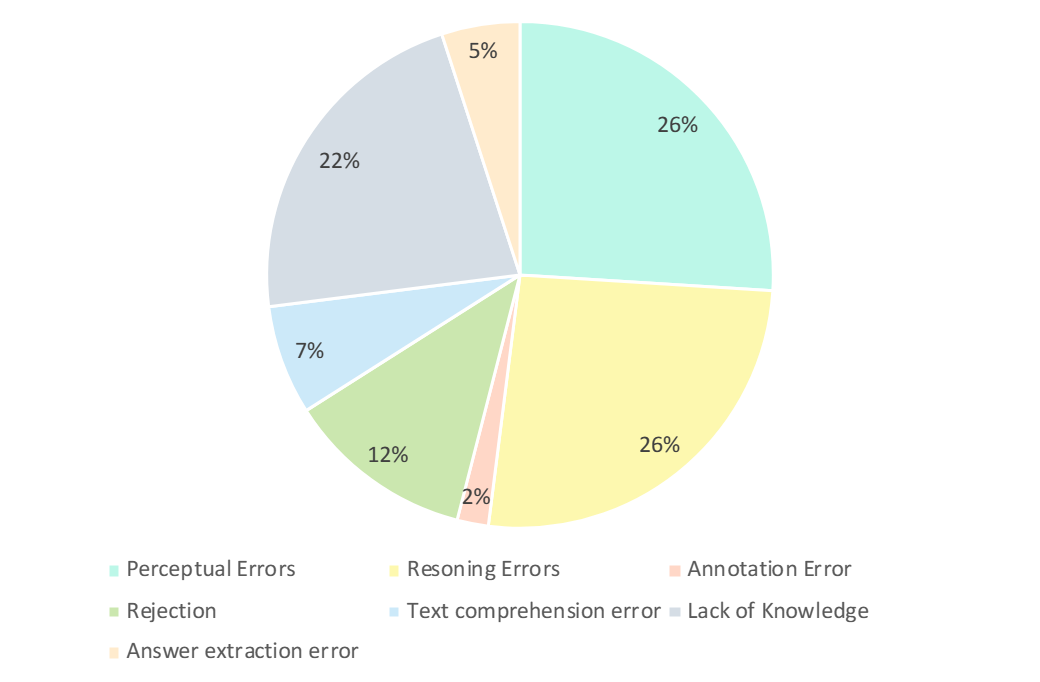
- 感知错误 (26%) : 感知错误是 GPT-4V 产生错误示例的主要原因之一。一方面,当模型无法理解图像时,会引入对图像基本感知的偏差,从而导致不正确的响应。另一方面,当模型遇到特定领域知识、隐含意义或不明确的公式中的歧义时,它往往表现出特定领域的知觉错误。在这种情况下,GPT-4V 倾向于更多地依赖基于文本信息的回答 (即问题和选项) ,优先考虑文本信息而不是视觉输入,从而导致理解多模态数据的偏差。
- 推理错误 (26%) : 推理错误是 GPT-4V 产生错误例子的另一个主要因素。在模型正确地感知到图像和文本所传达的意义的情况下,在解决需要复杂逻辑和数学推理的问题时,推理过程中仍会出现错误。通常,这种错误是由于模型较弱的逻辑和数学推理能力造成的。
- 缺乏知识 (22%) : 缺乏专业知识也是 GPT-4V 错误作答的原因之一。由于 CMMMU 是评价 LMM 专家 AGI 的基准,因此需要不同学科和子领域的专家级知识。因此,将专家级知识注入 LMM 也是可以努力的方向之一。
- 拒绝回答 (12%) : 模型拒绝回答也是一种常见的现象。通过分析,他们指出模型拒绝回答问题的几个原因: (1) 模型未能从图像中感知到信息;(2) 是涉及宗教问题或个人现实生活信息的问题,模型会主动回避;(3) 当问题涉及性别和主观因素时,模型避免直接提供答案。
- 其错误:其余的错误包括文本理解错误 (7%)、标注错误 (2%) 和答案提取错误 (5%)。这些错误是由于复杂的结构跟踪能力、复杂的文本逻辑理解、响应生成的局限性、数据标注的错误以及答案匹配提取中遇到的问题等多种因素造成的。
结论
CMMMU 基准测试标志着高级通用人工智能 (AGI) 开发的重大进展。CMMMU 的设计是为了严格评估最新的大型多模态模型 (LMMs) ,并测试基本的感知技能,复杂的逻辑推理,以及在特定领域的深刻专业知识。该研究通过比较中英双语语境下 LMM 的推理能力,指出其中的差异。这种详尽的评估对于判定模型水平与各个领域经验丰富的专业人员的熟练程度的差距至关重要。



