原标题:Radocc: Learning Cross-Modality Occupancy Knowledge through Rendering Assisted Distillation
论文链接:https://arxiv.org/pdf/2312.11829.pdf
作者单位:FNii, CUHK-Shenzhen SSE, CUHK-Shenzhen 华为诺亚方舟实验室
会议:AAAI 2024

论文思路:
3D 占用预测是一项新兴任务,旨在使用多视图图像估计 3D 场景的占用状态和语义。然而,由于缺乏几何先验,基于图像的场景感知在实现准确预测方面遇到了重大挑战。本文通过探索该任务中的跨模态知识蒸馏来解决这个问题,即,本文在训练过程中利用更强大的多模态模型来指导视觉模型。在实践中,本文观察到直接应用,在鸟瞰(BEV)感知中提出并广泛使用的特征或 logits 对齐,并不能产生令人满意的结果。为了克服这个问题,本文引入了 RadOcc,一种用于 3D 占用预测的渲染辅助蒸馏范式。通过采用可微体渲染(differentiable volume rendering),本文在透视图中生成深度和语义图,并提出了教师和学生模型的渲染输出之间的两个新颖的一致性标准(consistency criteria)。具体来说,深度一致性损失对齐渲染光线的终止分布(termination distributions),而语义一致性损失则模仿视觉基础模型(VLM)引导的 intra-segment 相似性。nuScenes 数据集上的实验结果证明了本文提出的方法在改进各种 3D 占用预测方法方面的有效性,例如,本文提出的方法在 mIoU 指标中将本文的基线提高了 2.2%,在 Occ3D 基准中达到了 50%。
主要贡献:
本文介绍了一种名为RadOcc的渲染辅助蒸馏范式,用于3D占用预测。这是第一篇探索3D-OP中跨模态知识蒸馏的论文,为现有BEV蒸馏技术在该任务中的应用提供了有价值的见解。
作者提出了两种新颖的蒸馏约束,即渲染深度和语义一致性(RDC和RSC)。这些约束通过对齐由视觉基础模型引导的光线分布和关联矩阵,有效地增强了知识迁移过程。这种方法的关键在于利用深度和语义信息来引导渲染过程,从而提高了渲染结果的质量和准确性。通过将这两种约束结合起来,研究人员取得了显著的改进,为视觉任务中的知识迁移提供了新的解决方案。
配备所提出的方法,RadOcc 在 Occ3D 和 nuScenes 基准上表现出了最先进的密集和稀疏占用预测性能。此外,实验证明了本文提出的蒸馏方法可以有效地提升多个基线模型的性能。
网络设计:
本文首次研究了针对3D占用预测任务的跨模态知识蒸馏。以BEV感知领域利用BEV或logits一致性进行知识迁移的方法为基础,本文将这些蒸馏技术扩展到3D占用预测任务中,旨在对齐体素特征和体素logits,如图1(a)所示。然而,初步实验表明,这些对齐技术在3D-OP任务中面临重大挑战,特别是前一种方法引入了负迁移。这一挑战可能源于3D目标检测和占用预测之间的根本差异,后者作为一项更细粒度的感知任务,需要捕获几何细节以及背景目标。
为了解决上述挑战,本文提出了 RadOcc,这是一种利用可微体渲染进行跨模态知识蒸馏的新颖方法。RadOcc的核心思想是对教师模型和学生模型生成的渲染结果进行对齐,如图1(b)所示。具体来说,本文使用相机的内参和外参对体素特征进行体渲染(Mildenhall et al. 2021),这使本文能够从不同的视点获得相应的深度图和语义图。为了实现渲染输出之间更好的对齐,本文引入了新颖的渲染深度一致性(RDC)和渲染语义一致性(RSC)损失。一方面,RDC 损失强制光线分布(ray distribution)的一致性,这使得学生模型能够捕获数据的底层结构。另一方面,RSC 损失利用了视觉基础模型的优势(Kirillov et al. 2023),并利用预先提取的 segment 进行 affinity 蒸馏。该标准允许模型学习和比较不同图像区域的语义表示,从而增强其捕获细粒度细节的能力。通过结合上述约束,本文提出的方法有效地利用了跨模态知识蒸馏,从而提高了性能并更好地优化了学生模型。本文展示了本文的方法在密集和稀疏占用预测方面的有效性,并在这两项任务上取得了最先进的结果。
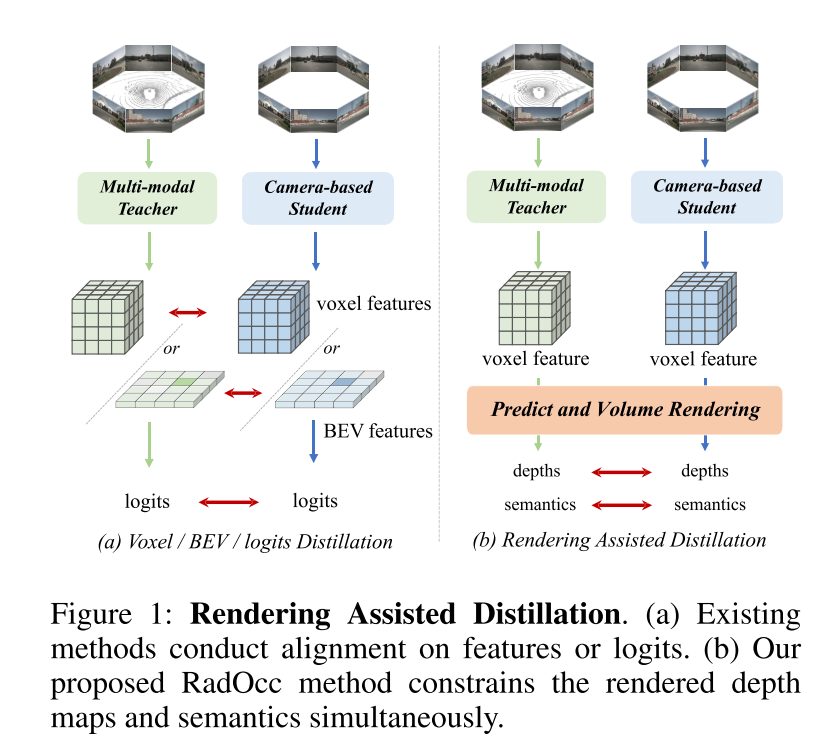
图 1:渲染辅助蒸馏。(a) 现有方法对特征或 logits 进行对齐。(b) 本文提出的 RadOcc 方法同时约束渲染的深度图和语义。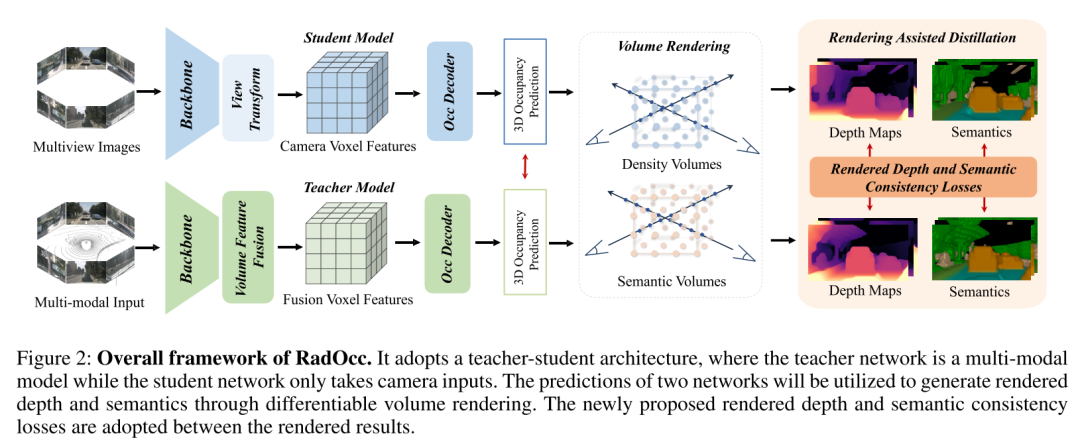 图2:RadOcc的总体框架。它采用师生架构,其中教师网络是多模态模型,而学生网络仅接受相机输入。两个网络的预测将用于通过可微分体渲染(differentiable volume rendering)生成渲染深度和语义。渲染结果之间采用了新提出的渲染深度和语义一致性损失。
图2:RadOcc的总体框架。它采用师生架构,其中教师网络是多模态模型,而学生网络仅接受相机输入。两个网络的预测将用于通过可微分体渲染(differentiable volume rendering)生成渲染深度和语义。渲染结果之间采用了新提出的渲染深度和语义一致性损失。
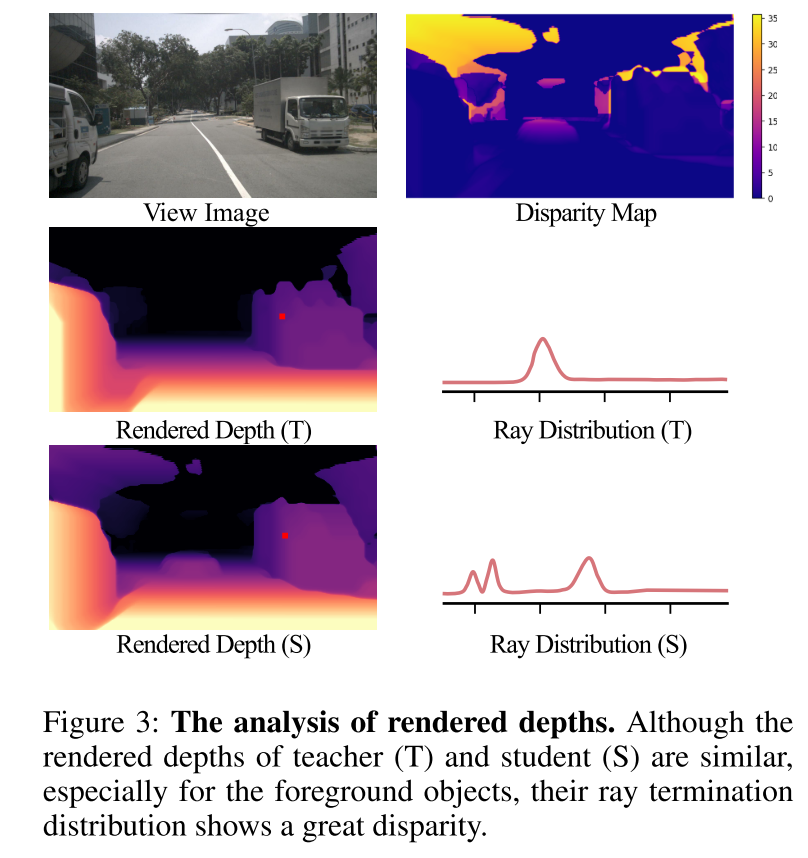
图 3:渲染深度分析。尽管教师(T)和学生(S)的渲染深度相似,特别是对于前景物体,但它们的光线终止分布显示出很大的差异。
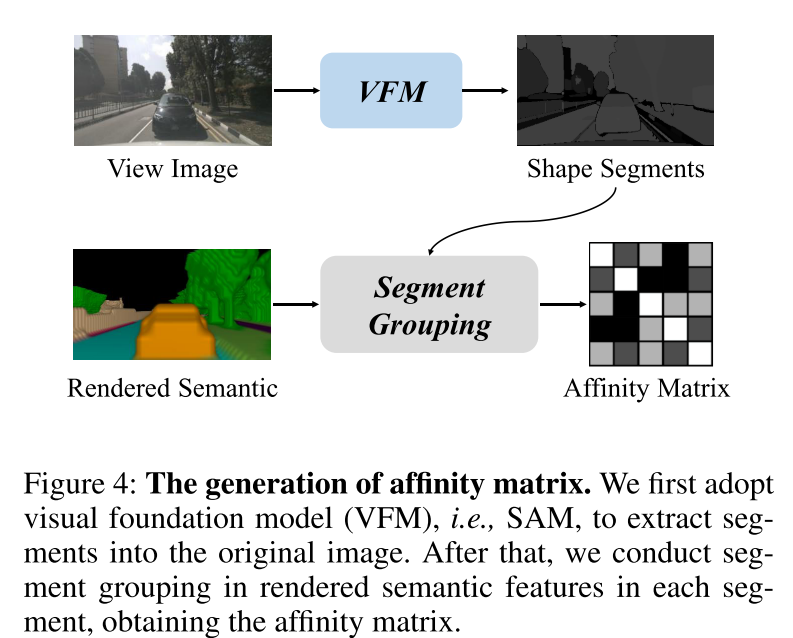
图 4:affinity matrix 的生成。本文首先采用视觉基础模型(VFM),即 SAM,将 segments 提取到原始图像中。之后,本文对每个 segment 中渲染的语义特征进行 segment 聚合,获得 affinity matrix 。
实验结果:
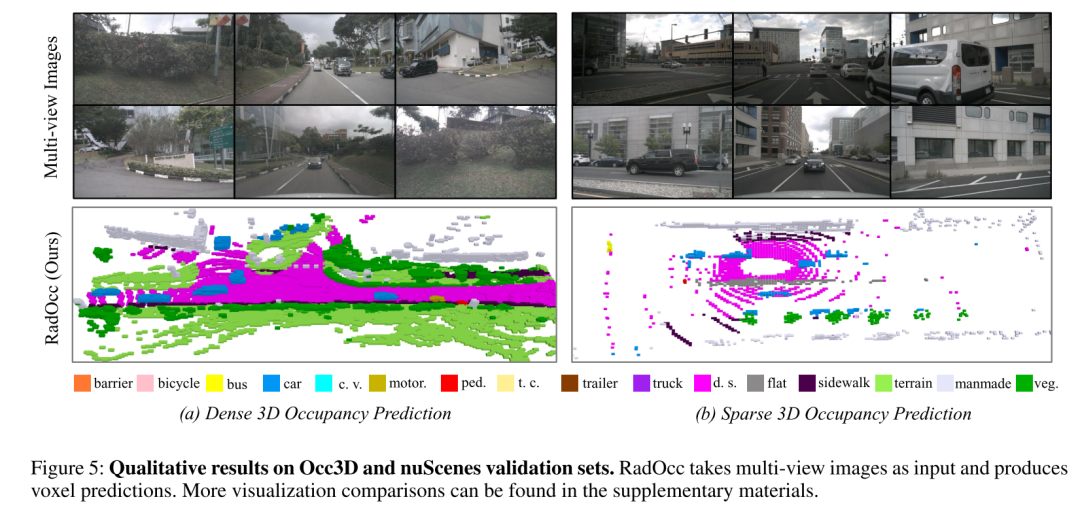
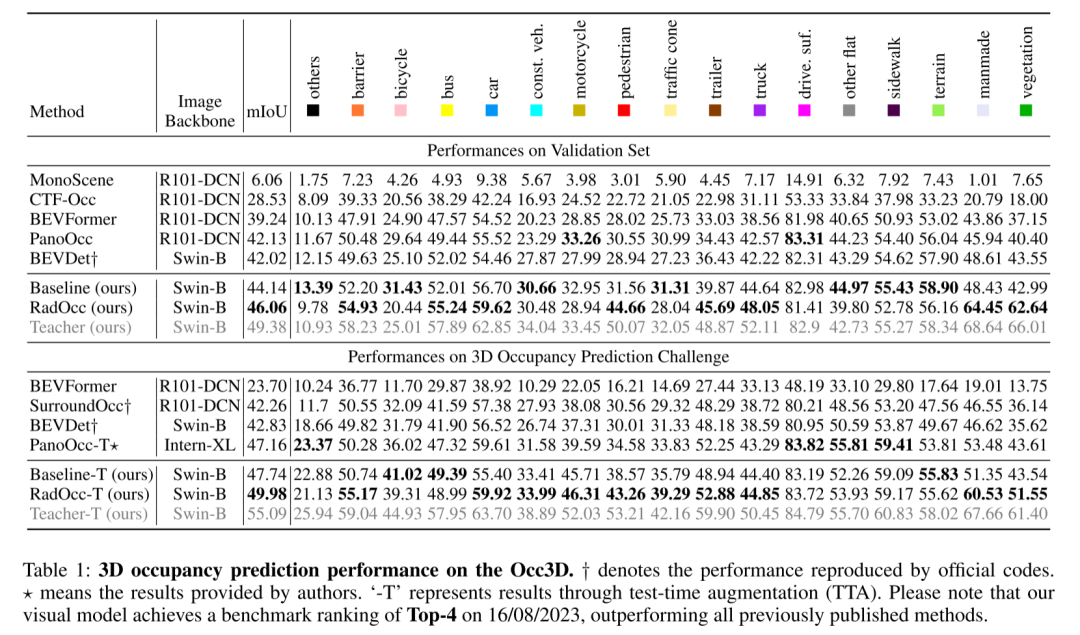
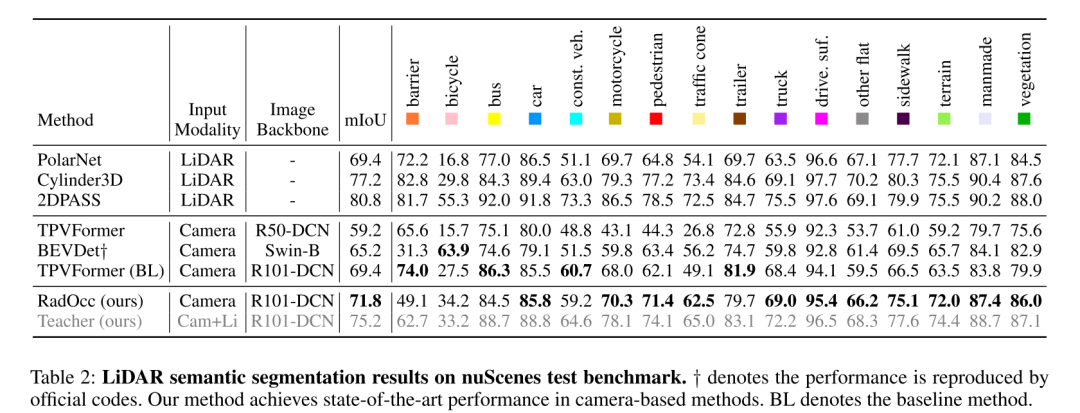
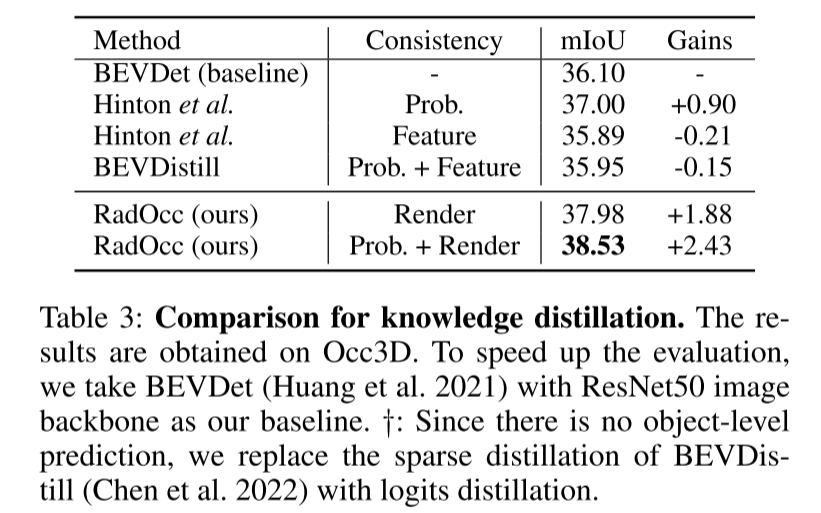
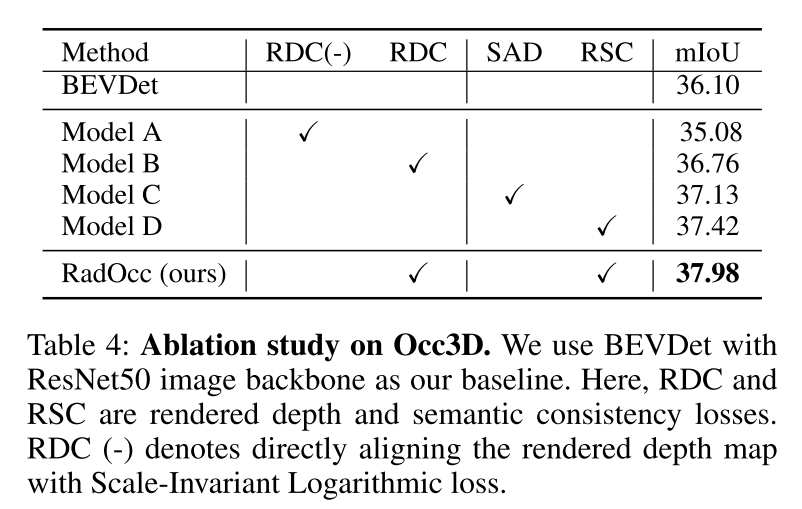
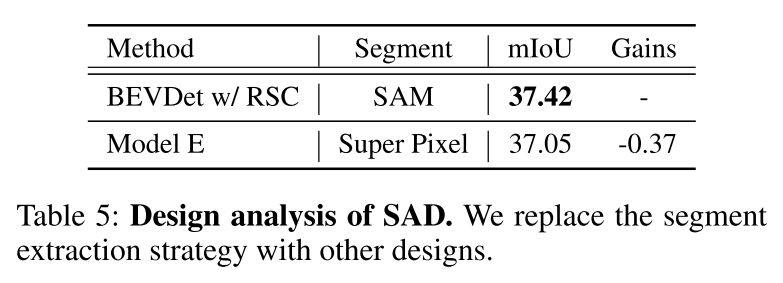
总结:
本文提出了 RadOcc,一种用于 3D 占用预测的新型跨模态知识蒸馏范式。它利用多模态教师模型通过可微分体渲染(differentiable volume rendering)为视觉学生模型提供几何和语义指导。此外,本文提出了两个新的一致性标准,深度一致性损失和语义一致性损失,以对齐教师和学生模型之间的 ray distribution 和 affinity matrix 。对 Occ3D 和 nuScenes 数据集的大量实验表明,RadOcc 可以显着提高各种 3D 占用预测方法的性能。本文的方法在 Occ3D 挑战基准上取得了最先进的结果,并且大大优于现有已发布的方法。本文相信本文的工作为场景理解中的跨模态学习开辟了新的可能性。



