论文:https://arxiv.org/pdf/2309.03852.pdf
需要重写的内容是:模型链接:https://huggingface.co/CofeAI/FLM-101B
语言本质上是符号的。已经有一些研究在使用符号而非类别标签来评估 LLM 的智能水平。类似地,该团队使用了一种符号映射方法来测试 LLM 在未曾见过的上下文上的泛化能力。
人类智能的一大重要能力是理解给定的规则并采取相应的行动。这种测试方法已被广泛用在各种等级的测验中。因此,规则理解成为这里的第二项测试。
重写后的内容:模式挖掘是智能的重要组成部分,它涉及到归纳和演绎。在科学发展历史中,这种方法起着至关重要的作用。此外,各种竞赛的测试题也常常需要这种能力才能解答。出于这些原因,我们选择了模式挖掘作为第三个评估指标
最后一个也很重要的指标是抗干扰能力,这也是智能的核心能力之一。已有研究指出,语言和图像都很容易被噪声干扰。考虑到这一点,该团队把抗干扰用作了最后一个评估指标。
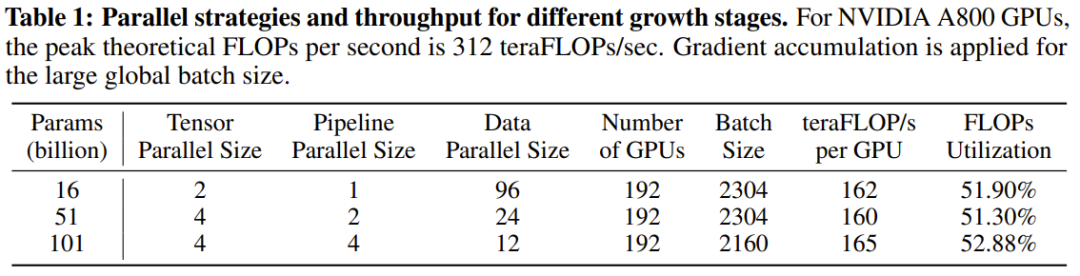
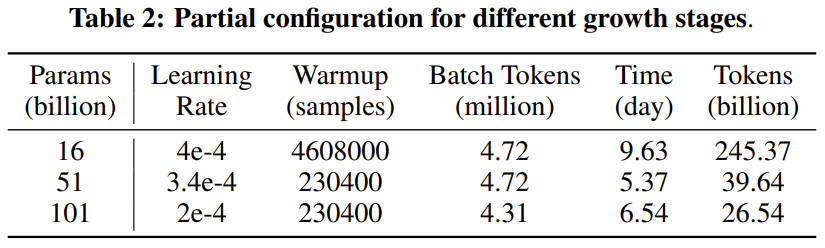
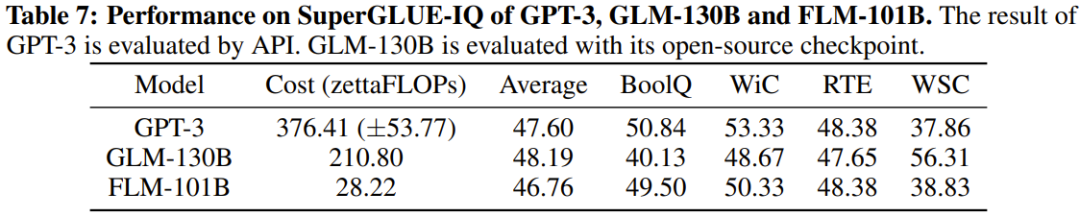
研究者表示,这是一个使用增长策略从头开始训练超过千亿参数的LLM研究尝试。同时,这也是目前成本最低的千亿参数模型,仅需10万美元成本
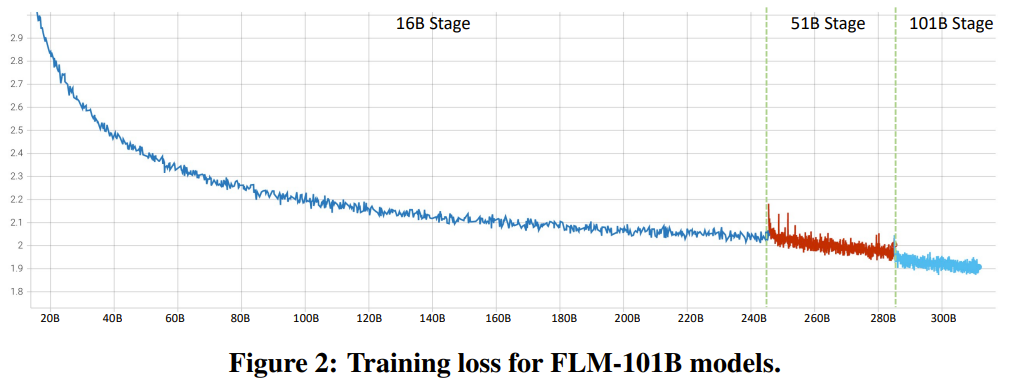
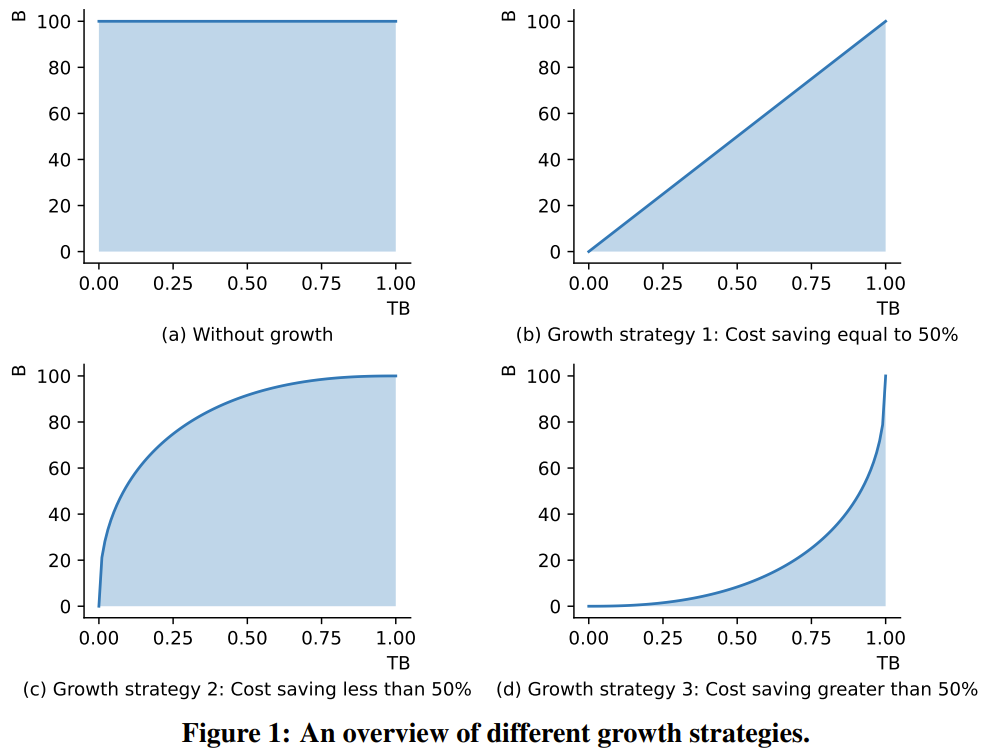
通过改进 FreeLM 训练目标、有潜力的超参数搜索方法和功能保留型增长,这项研究解决了不稳定问题。研究者相信该方法也能为更广大的科研社区提供助力。
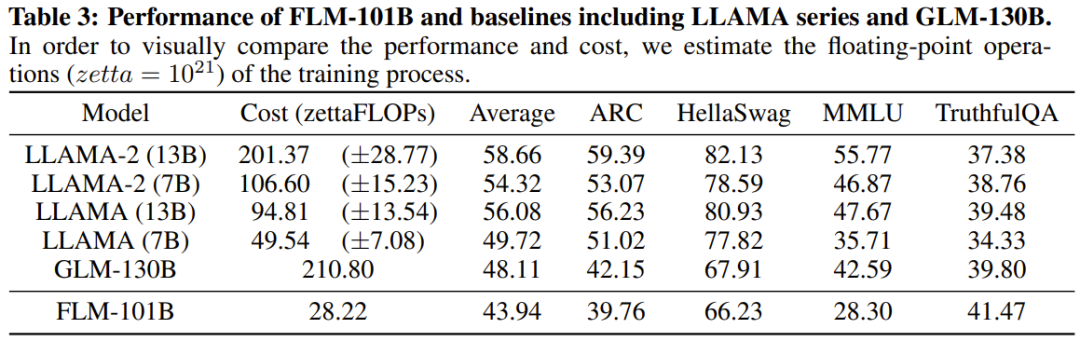
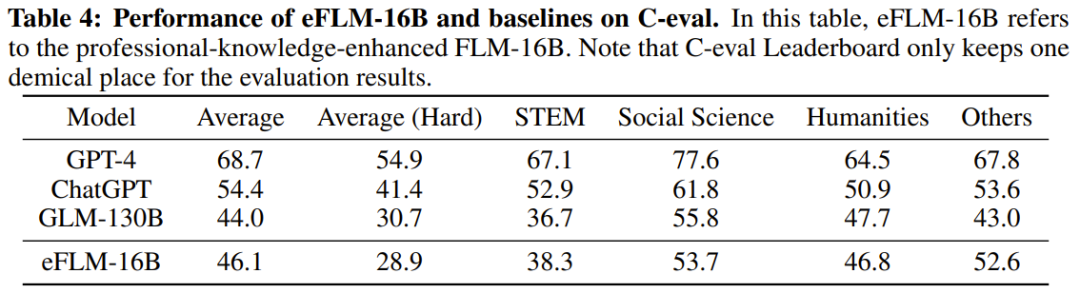
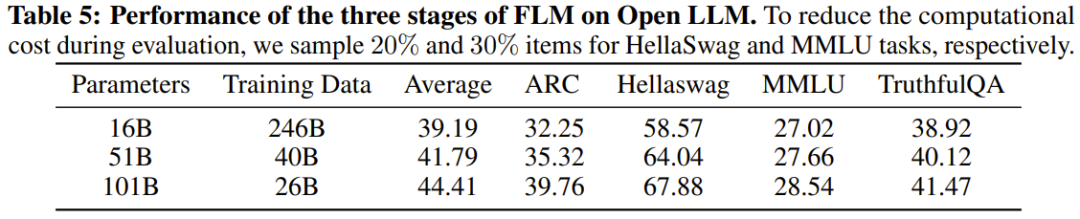
研究人员还对新模型与之前的强大模型进行了实验比较,包括使用面向知识的基准和新提出的系统性IQ评估基准。实验结果显示,FLM-101B模型具有竞争力且稳健
该团队会发布模型检查点、代码、相关工具等,以推进千亿参数规模的汉语和英语双语 LLM 的研究开发。